Preliminary
Basic Concepts
状态(State) :在时间步 t t t s t s_{t} s t q q q o < t o_{<t} o < t s t = [ q , o < t ] s_{t} = [q,o_{<t}] s t = [ q , o < t ]
s 1 = q ∼ p Q s_{1} = q \sim p_{\mathcal{Q}} s 1 = q ∼ p Q s 1 s_{1} s 1 p Q p_{\mathcal{Q}} p Q q q q o < t = [ o 1 , o 2 , … , o t − 1 ] o_{<t}=[o_{1},o_{2},\ldots,o_{t-1}] o < t = [ o 1 , o 2 , … , o t − 1 ] t t t s t + 1 = [ s t ; o t ] = [ q ; o < t + 1 ] s_{t+1} = [s_{t};o_{t}] = [q;o_{<t+1}] s t + 1 = [ s t ; o t ] = [ q ; o < t + 1 ] s t + 1 s_{t+1} s t + 1
动作(Action) :在当前状态 s t s_{t} s t a t a_{t} a t V \mathcal{V} V o t o_{t} o t a t = o t a_{t} = o_{t} a t = o t 策略(Policy) :策略 π \pi π θ \theta θ s t = [ q , o < t ] s_{t} = [q,o_{<t}] s t = [ q , o < t ] π ( ⋅ ∣ q , o < t ) \pi(\cdot \mid q,o_{<t}) π ( ⋅ ∣ q , o < t ) V \mathcal{V} V
π θ \pi_{\theta} π θ θ \theta θ π θ o l d \pi_{\theta_{old}} π θ o l d π θ \pi_{\theta} π θ r t ( θ ) r_{t}(\theta) r t ( θ ) π θ \pi_{\theta} π θ π r e f \pi_{ref} π re f
状态转移(State Transition) :在当前状态 s t s_{t} s t o t o_{t} o t s t + 1 = [ s t ; o t ] = [ q ; o < t + 1 ] s_{t+1} = [s_{t};o_{t}] = [q;o_{<t+1}] s t + 1 = [ s t ; o t ] = [ q ; o < t + 1 ] P ( s t + 1 ∣ s t , o t ) = 1 P(s_{t+1} \mid s_{t},o_{t}) = 1 P ( s t + 1 ∣ s t , o t ) = 1 轨迹(Trajectory, a.k.a. Episode or Rollout) :一个完整的生成序列 τ \tau τ q q q q q q o = [ o 1 , o 2 , … , o ∣ o ∣ ] o = [o_{1},o_{2},\ldots,o_{|o|}] o = [ o 1 , o 2 , … , o ∣ o ∣ ]
Reward and Return
传统 RL 中,奖励函数 R ( s t , a t , s t + 1 ) R(s_{t},a_{t},s_{t+1}) R ( s t , a t , s t + 1 ) R ( q , o ≤ t ) R(q,o_{\le t}) R ( q , o ≤ t )
Outcome-based Reward
在这种设定下,奖励信号是稀疏的,仅在 response o o o r ( q , o ) r(q,o) r ( q , o )
对于轨迹中任意中间时刻 t < ∣ o ∣ t<|o| t < ∣ o ∣ R t = 0 R_{t} = 0 R t = 0
只有在最后一个时间步 t = ∣ o ∣ t=|o| t = ∣ o ∣ R t = r ( q , o ) R_{t} = r(q,o) R t = r ( q , o )
形式化地,对于任意时间步 t t t
R ( q , o ≤ t ) = I ( o t = [ EOS ] ) r ( q , o ) R(q,o_{\le t}) = \mathbf{I}(o_{t} = [\text{EOS}])r(q,o)
R ( q , o ≤ t ) = I ( o t = [ EOS ]) r ( q , o )
其中,I ( o t = [ EOS ] ) \mathbf{I}(o_{t} = [\text{EOS}]) I ( o t = [ EOS ]) o t o_{t} o t 1 1 1 0 0 0
更进一步,对于任意时间步 t t t G t G_{t} G t γ = 1 \gamma=1 γ = 1
G t = ∑ t ′ = t ∣ o ∣ R t ′ = R ( q , o ≤ t ′ ) + R ( q , o ≤ t ′ + 1 ) + ⋯ + R ( q , o ≤ ∣ o ∣ ) = 0 + 0 + ⋯ + R ( q , o ≤ ∣ o ∣ ) = R ( q , o ≤ ∣ o ∣ ) = r ( q , o ) \begin{aligned}
G_{t}
&= \sum_{t^{\prime}=t}^{|o|} R_{t^{\prime}} \\
&= R(q,o_{\le t^{\prime}}) + R(q,o_{\le t^{\prime} +1}) + \cdots + R(q,o_{\le |o|}) \\
&= 0 + 0 + \cdots + R(q,o_{\le |o|}) \\
&= R(q,o_{\le |o|}) \\
&= r(q,o)
\end{aligned}
G t = t ′ = t ∑ ∣ o ∣ R t ′ = R ( q , o ≤ t ′ ) + R ( q , o ≤ t ′ + 1 ) + ⋯ + R ( q , o ≤ ∣ o ∣ ) = 0 + 0 + ⋯ + R ( q , o ≤ ∣ o ∣ ) = R ( q , o ≤ ∣ o ∣ ) = r ( q , o )
虽然稀疏奖励实现简单,但存在信用分配问题(Credit Assignment Problem),难以判断哪个具体的 token 导致了最终奖励的高低。
本文使用 G t G_{t} G t G G G R R R G t G_{t} G t
Process-based Reward
为了缓解稀疏奖励的信用分配问题,提供更稠密的信号,可以通过过程奖励模型(Process Reward Model, PRM)为生成过程中每个步骤 t t t r ( q , o ≤ t ) r(q,o_{\le t}) r ( q , o ≤ t ) R t = R ( q , o ≤ t ) = r ( q , o ≤ t ) R_{t} = R(q,o_{\le t}) = r(q,o_{\le t}) R t = R ( q , o ≤ t ) = r ( q , o ≤ t ) R ( q , o ≤ t ) R(q,o_{\le t}) R ( q , o ≤ t )
在此设定下,一条完整轨迹 o o o
G ( q , o ) = ∑ t = 1 ∣ o ∣ R ( q , o ≤ t ) G(q,o) = \sum_{t=1}^{|o|} R(q,o_{\le t})
G ( q , o ) = t = 1 ∑ ∣ o ∣ R ( q , o ≤ t )
而从时间步 t t t
G t = G ( q , o ≤ t ) = ∑ t ′ = t ∣ o ∣ R ( q , o ≤ t ′ ) G_{t} = G(q,o_{\le t}) = \sum_{t^{\prime}=t}^{|o|}R(q,o_{\le t^{\prime}})
G t = G ( q , o ≤ t ) = t ′ = t ∑ ∣ o ∣ R ( q , o ≤ t ′ )
实际上,不论是稀疏奖励还是稠密奖励,回报都可以表示如上。
KL-Shaped Reward
在 RL-tuning 过程中,仅依赖于 RM 的信号引导,策略 π θ \pi_{\theta} π θ D KL ( π θ ∥ π r e f ) \mathbb{D}_{\text{KL}}(\pi_{\theta} \| \pi_{ref}) D KL ( π θ ∥ π re f ) π θ \pi_{\theta} π θ π r e f \pi_{ref} π re f
当奖励模型为 ORM 时,复合奖励表示如下:
R ( q , o ≤ t ) = I ( o t = [ EOS ] ) r ( q , o ) − β KL t R(q,o_{\le t}) = \mathbf{I}(o_{t} = [\text{EOS}])r(q,o) - \beta \text{KL}_{t}
R ( q , o ≤ t ) = I ( o t = [ EOS ]) r ( q , o ) − β KL t
其中,β \beta β KL t \text{KL}_{t} KL t k 1 k_{1} k 1
KL t = log π θ o l d ( o t ∣ q , o < t ) π r e f ( o t ∣ q , o < t ) \text{KL}_{t} = \log \frac{\pi_{\theta_{old}}(o_{t} \mid q,o_{<t})}{\pi_{ref}(o_{t} \mid q,o_{<t})}
KL t = log π re f ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t )
此时,由于奖励函数中加入了 KL 散度,稀疏奖励变得稠密化,PPO 使用的就是这种 token-level 奖励。而 RLOO 为了使奖励信号再次稀疏化,将整个序列的 KL 惩罚聚合起来,只在最后一个时间步与 ORM 奖励一同发放:
R ( q , o ) = r ( q , o ) − β ∑ t = 1 ∣ o ∣ KL t R(q,o) = r(q,o) - \beta \sum_{t=1}^{|o|} \text{KL}_{t}
R ( q , o ) = r ( q , o ) − β t = 1 ∑ ∣ o ∣ KL t
特别地,在 RL-tuning reasoning model 中,ORM 通常为 rule-based verifier,通常不会引起分布漂移。此时,将移除 KL 惩罚项,省去了 Ref Model 的加载。
Objective Function
在 RLHF 中,我们的目标是最大化 J ( θ ) J(\theta) J ( θ )
max θ J ( θ ) = E q ∼ p Q [ E o ∼ π θ ( ⋅ ∣ q ) [ G ( q , o ) ] ] \max_{\theta}J(\theta) = \mathbb{E}_{q \sim p_{\mathcal{Q}}} \Big[\mathbb{E}_{o \sim \pi_{\theta}(\cdot \mid q)} \big[G(q, o)\big]\Big]
θ max J ( θ ) = E q ∼ p Q [ E o ∼ π θ ( ⋅ ∣ q ) [ G ( q , o ) ] ]
其中:
G ( q , o ) = ∑ t = 1 ∣ o ∣ R ( q , o ≤ t ) G(q,o) = \sum_{t=1}^{|o|}R(q,o_{\le t}) G ( q , o ) = ∑ t = 1 ∣ o ∣ R ( q , o ≤ t ) R ( q , o ≤ t ) R(q,o_{\le t}) R ( q , o ≤ t ) o o o t t t
接下来,策略梯度推导如下:
∇ θ J ( θ ) = E q ∼ p Q [ E o ∼ π θ ( ⋅ ∣ q ) [ ∇ θ log π θ ( o ∣ q ) G ( q , o ) ] ] = E q ∼ p Q [ E o ∼ π θ ( ⋅ ∣ q ) [ ∇ θ ∑ t = 1 ∣ o ∣ log π θ ( o t ∣ q , o < t ) G ( q , o ) ] ] = E q ∼ p Q [ E o ∼ π θ ( ⋅ ∣ q ) [ ∑ t = 1 ∣ o ∣ ∇ θ log π θ ( o t ∣ q , o < t ) ∑ t ′ = t ∣ o ∣ R ( q , o ≤ t ′ ) ] ] = E q ∼ p Q [ E o ∼ π θ ( ⋅ ∣ q ) [ ∑ t = 1 ∣ o ∣ ∇ θ log π θ ( o t ∣ q , o < t ) ( ∑ t ′ = t ∣ o ∣ R ( q , o ≤ t ′ ) − b ( q , o < t ) ) ] ] \begin{aligned}
\nabla_{\theta} J(\theta)
&= \mathbb{E}_{q \sim p_{\mathcal{Q}}}\bigg[ \mathbb{E}_{o \sim \pi_{\theta}(\cdot \mid q)}\big[ \nabla_{\theta} \log \pi_{\theta}(o \mid q) G(q, o)\big]\bigg] \\
&= \mathbb{E}_{q \sim p_{\mathcal{Q}}}\bigg[ \mathbb{E}_{o \sim \pi_{\theta}(\cdot \mid q)}\Big[ \nabla_{\theta} \sum_{t=1}^{|o|} \log \pi_{\theta}(o_{t} \mid q, o_{<t}) G(q, o)\Big]\bigg] \\
&= \mathbb{E}_{q \sim p_{\mathcal{Q}}}\bigg[ \mathbb{E}_{o \sim \pi_{\theta}(\cdot \mid q)}\Big[ \sum_{t=1}^{|o|} \nabla_{\theta} \log \pi_{\theta}(o_{t} \mid q, o_{<t}) \sum_{t^{\prime}=t}^{|o|} R(q, o_{\le t^{\prime}})\Big]\bigg] \\
&= \mathbb{E}_{q \sim p_{\mathcal{Q}}}\Bigg[ \mathbb{E}_{o \sim \pi_{\theta}(\cdot \mid q)}\bigg[ \sum_{t=1}^{|o|} \nabla_{\theta} \log \pi_{\theta}(o_{t} \mid q, o_{<t}) \bigg( \sum_{t^{\prime}=t}^{|o|} R(q, o_{\le t^{\prime}}) - b(q, o_{<t}) \bigg) \bigg]\Bigg]
\end{aligned}
∇ θ J ( θ ) = E q ∼ p Q [ E o ∼ π θ ( ⋅ ∣ q ) [ ∇ θ log π θ ( o ∣ q ) G ( q , o ) ] ] = E q ∼ p Q [ E o ∼ π θ ( ⋅ ∣ q ) [ ∇ θ t = 1 ∑ ∣ o ∣ log π θ ( o t ∣ q , o < t ) G ( q , o ) ] ] = E q ∼ p Q [ E o ∼ π θ ( ⋅ ∣ q ) [ t = 1 ∑ ∣ o ∣ ∇ θ log π θ ( o t ∣ q , o < t ) t ′ = t ∑ ∣ o ∣ R ( q , o ≤ t ′ ) ] ] = E q ∼ p Q [ E o ∼ π θ ( ⋅ ∣ q ) [ t = 1 ∑ ∣ o ∣ ∇ θ log π θ ( o t ∣ q , o < t ) ( t ′ = t ∑ ∣ o ∣ R ( q , o ≤ t ′ ) − b ( q , o < t ) ) ] ]
其中,b ( q , o < t ) b(q,o_{<t}) b ( q , o < t ) o t o_{t} o t 0 0 0
E o t ∼ π θ ( ⋅ ∣ q , o < t ) [ ∇ θ log π θ ( o t ∣ q , o < t ) b ( q , o < t ) ] = 0 \mathbb{E}_{o_{t} \sim \pi_{\theta}(\cdot \mid q,o_{<t})} \Big[ \nabla_{\theta} \log \pi_{\theta}(o_{t} \mid q,o_{<t}) b(q,o_{<t}) \Big] = 0
E o t ∼ π θ ( ⋅ ∣ q , o < t ) [ ∇ θ log π θ ( o t ∣ q , o < t ) b ( q , o < t ) ] = 0
通常,baseline 可以设置为未来期望回报,在传统 RL 中表示为状态价值 V π ( s t ) V^{\pi}(s_{t}) V π ( s t )
b ( q , o < t ) = V π ( q , o < t ) = E o ≥ t ∼ π θ ( ⋅ ∣ q , o < t ) [ ∑ t ′ = t ∣ o ∣ R ( q , o ≤ t ′ ) ] b(q,o_{<t}) = V^{\pi}(q,o_{<t}) = \mathbb{E}_{o_{\ge t} \sim \pi_{\theta}(\cdot \mid q,o_{<t})} \bigg[ \sum_{t^{\prime}=t}^{|o|} R(q, o_{\le t^{\prime}}) \bigg]
b ( q , o < t ) = V π ( q , o < t ) = E o ≥ t ∼ π θ ( ⋅ ∣ q , o < t ) [ t ′ = t ∑ ∣ o ∣ R ( q , o ≤ t ′ ) ]
为了简化表示,我们定义 t t t A t A_{t} A t
A t = G t − b ( q , o < t ) = ∑ t ′ = t ∣ o ∣ R ( q , o ≤ t ′ ) − b ( q , o < t ) A_{t} = G_{t} - b(q,o_{<t}) = \sum_{t^{\prime}=t}^{|o|} R(q, o_{\le t^{\prime}}) - b(q, o_{<t})
A t = G t − b ( q , o < t ) = t ′ = t ∑ ∣ o ∣ R ( q , o ≤ t ′ ) − b ( q , o < t )
此时,策略梯度可以简化为:
∇ θ J ( θ ) = E q ∼ p Q , o ∼ π θ ( ⋅ ∣ q ) [ ∑ t = 1 ∣ o ∣ ∇ θ log π θ ( o t ∣ q , o < t ) A t ] \nabla_{\theta} J(\theta) = \mathbb{E}_{q \sim p_{\mathcal{Q}},o \sim \pi_{\theta}(\cdot \mid q)}\Bigg[ \sum_{t=1}^{|o|} \nabla_{\theta} \log \pi_{\theta}(o_{t} \mid q, o_{<t}) A_{t} \Bigg]
∇ θ J ( θ ) = E q ∼ p Q , o ∼ π θ ( ⋅ ∣ q ) [ t = 1 ∑ ∣ o ∣ ∇ θ log π θ ( o t ∣ q , o < t ) A t ]
不同的算法使用不同的 advantage estimator A ^ t \hat{A}_{t} A ^ t
REINFORCE
REINFORCE 使用轨迹中实际采样得到的真实奖励和来近似回报(a.k.a., 蒙特卡洛回报)。具体实现中,可以不使用 value network 来近似 baseline。REINFORCE 的特点是无偏高方差:
无偏:蒙特卡洛回报是对策略梯度的无偏估计
高方差:蒙特卡洛回报是一个很长的随机变量 R R R
PPO: Proximal Policy Optimization
PPO 的奖励信号通常采用典型的 token-level 的 KL-shaped reward:
R ( q , o ≤ t ) = I ( o t = [ EOS ] ) r ( q , o ) − β KL t R(q,o_{\le t}) = \mathbf{I}(o_{t} = [\text{EOS}])r(q,o) - \beta \text{KL}_{t}
R ( q , o ≤ t ) = I ( o t = [ EOS ]) r ( q , o ) − β KL t
其中,r ( q , o ) r(q,o) r ( q , o )
PPO 采用重要性网络,希望复用旧策略 π θ o l d \pi_{\theta_{old}} π θ o l d π θ \pi_{\theta} π θ J ( θ ) J(\theta) J ( θ )
J ( θ ) = E q ∼ p Q [ E o ∼ π θ o l d ( ⋅ ∣ q ) [ ∑ t = 1 ∣ o ∣ min ( r t ( θ ) A ^ t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] ] \begin{aligned}
J(\theta) = \mathbb{E}_{q \sim p_{\mathcal{Q}}}\Bigg[ \mathbb{E}_{o \sim \pi_{\theta_{old}}(\cdot \mid q)} \bigg[ \sum_{t=1}^{|o|} \min\Big(
r_{t}(\theta) \hat{A}_{t},
\mathrm{clip}\big(r_{t}(\theta),1-\epsilon,1+\epsilon\big)\hat{A}_{t}
\Big)\bigg] \Bigg]
\end{aligned}
J ( θ ) = E q ∼ p Q [ E o ∼ π θ o l d ( ⋅ ∣ q ) [ t = 1 ∑ ∣ o ∣ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] ]
其中,c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) \mathrm{clip}\big(r_{t}(\theta),1-\epsilon,1+\epsilon\big) clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) r t ( θ ) r_{t}(\theta) r t ( θ ) [ 1 − ϵ , 1 + ϵ ] [1-\epsilon,1+\epsilon] [ 1 − ϵ , 1 + ϵ ] ϵ \epsilon ϵ r t ( θ ) r_{t}(\theta) r t ( θ )
r t ( θ ) = π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) r_{t}(\theta) = \frac{\pi_{\theta}(o_{t} \mid q,o_{<t})}{\pi_{\theta_{old}}(o_{t} \mid q,o_{<t})}
r t ( θ ) = π θ o l d ( o t ∣ q , o < t ) π θ ( o t ∣ q , o < t )
优势使用 GAE A ^ t G A E ( γ , λ ) \hat{A}_{t}^{\mathrm{GAE}(\gamma,\lambda)} A ^ t GAE ( γ , λ ) λ \lambda λ
RLOO: REINFORCE Leave One Out
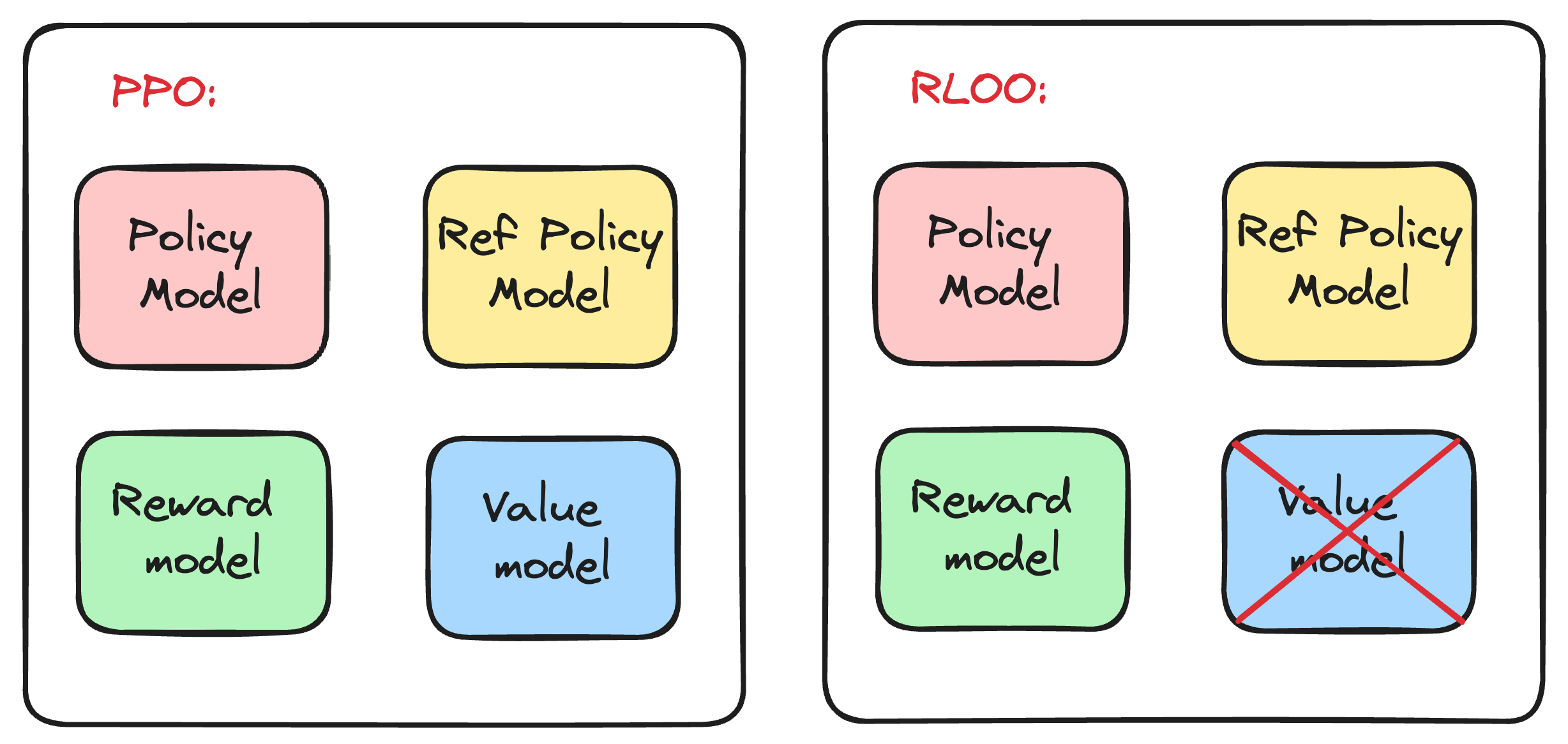
RLOO 的核心动机在于丢弃 PPO 中的 value network,从而节省显存占用,如下图所示。
baseline 一般被设计为状态价值,这通常需要 value network 来近似。RLOO 通过对单个 prompt q q q G G G { o i } i = 1 G \{o_{i}\}_{i=1}^{G} { o i } i = 1 G
RLOO 与 PPO 不同,后者采用 token-level 的 KL-shaped reward 奖励信号,而前者采用 response-level 的稀疏奖励信号。换句话说,对于一条 response,只有唯一的即时奖励 R ( q , o ) R(q,o) R ( q , o ) G ( q , o ) G(q,o) G ( q , o )
R ( q , o ) = r ( q , o ) − β ∑ t = 1 ∣ o ∣ KL t R(q,o) = r(q,o) - \beta \sum_{t=1}^{|o|} \text{KL}_{t}
R ( q , o ) = r ( q , o ) − β t = 1 ∑ ∣ o ∣ KL t
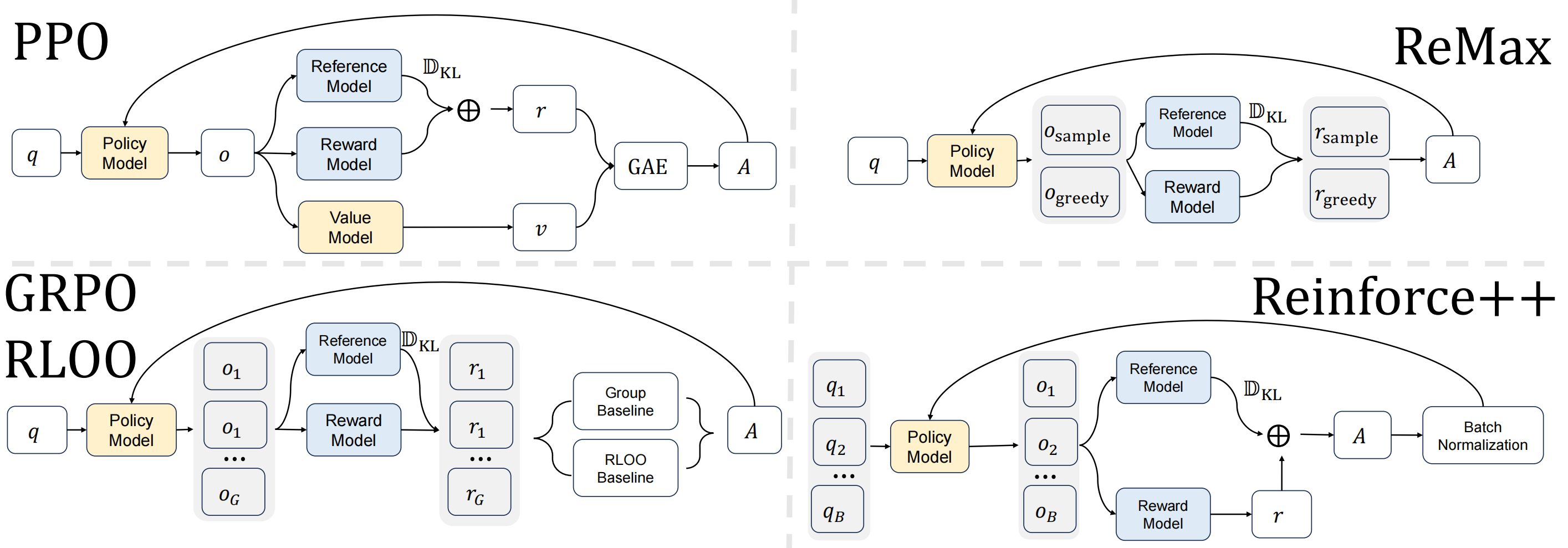
下图对比了 PPO 和 RLOO 的奖励计算:
RLOO 将 group 中的样本 o i o_{i} o i b ( q , o i ) b(q,o_{i}) b ( q , o i ) G − 1 G-1 G − 1
b ( q , o i ) = 1 G − 1 ∑ j = 1 , j ≠ i G G ( q , o j ) = 1 G − 1 ∑ j = 1 , j ≠ i G R ( q , o j ) \begin{aligned}
b(q,o_{i}) &= \frac{1}{G-1} \sum_{j=1,j \ne i}^{G} G(q,o_{j}) \\
&= \frac{1}{G-1} \sum_{j=1,j \ne i}^{G} R(q,o_{j})
\end{aligned}
b ( q , o i ) = G − 1 1 j = 1 , j = i ∑ G G ( q , o j ) = G − 1 1 j = 1 , j = i ∑ G R ( q , o j )
由于剔除了自身样本的奖励,因此 b ( q , o i ) b(q,o_{i}) b ( q , o i ) o i , t o_{i,t} o i , t 0 0 0 o i , t o_{i,t} o i , t o i o_{i} o i t t t
A ^ i = G ( q , o i ) − b ( q , o i ) = R ( q , o i ) − 1 G − 1 ∑ j = 1 , j ≠ i G R ( q , o j ) = R ( q , o i ) − 1 G − 1 ( ∑ j = 1 G R ( q , o j ) − R ( q , o i ) ) = G G − 1 R ( q , o i ) − 1 G − 1 ∑ j = 1 G R ( q , o j ) = G G − 1 ( R ( q , o i ) − 1 G ∑ j = 1 G R ( q , o j ) ) \begin{aligned}
\hat{A}_{i} &= G(q,o_{i}) - b(q,o_{i}) \\
&= R(q,o_{i}) - \frac{1}{G-1} \sum_{j=1,j \ne i}^{G} R(q,o_{j}) \\
&= R(q,o_{i}) - \frac{1}{G-1} \bigg( \sum_{j=1}^{G} R(q,o_{j}) - R(q,o_{i}) \bigg)\\
&= \frac{G}{G-1} R(q,o_{i}) - \frac{1}{G-1} \sum_{j=1}^{G} R(q,o_{j}) \\
&= \frac{G}{G-1} \bigg( R(q,o_{i}) - \frac{1}{G} \sum_{j=1}^{G} R(q,o_{j}) \bigg)
\end{aligned}
A ^ i = G ( q , o i ) − b ( q , o i ) = R ( q , o i ) − G − 1 1 j = 1 , j = i ∑ G R ( q , o j ) = R ( q , o i ) − G − 1 1 ( j = 1 ∑ G R ( q , o j ) − R ( q , o i ) ) = G − 1 G R ( q , o i ) − G − 1 1 j = 1 ∑ G R ( q , o j ) = G − 1 G ( R ( q , o i ) − G 1 j = 1 ∑ G R ( q , o j ) )
直观地,优势 A ^ i \hat{A}_{i} A ^ i o i o_{i} o i G − 1 G-1 G − 1 o j ( j ≠ i ) o_{j}(j \ne i) o j ( j = i )
如果 A ^ i > 0 \hat{A}_{i} > 0 A ^ i > 0 o i o_{i} o i
如果 A ^ i < 0 \hat{A}_{i} < 0 A ^ i < 0 o i o_{i} o i
这里也可以看出与 PPO 的 GAE 优势的差距:PPO GAE 是 token-level 的优势,而 RLOO 将 o i o_{i} o i o i , t o_{i,t} o i , t A ^ i , t = A ^ i \hat{A}_{i,t} = \hat{A}_{i} A ^ i , t = A ^ i
最后,RLOO 策略梯度计算如下:
∇ θ J ( θ ) = E q ∼ p Q [ E { o i } i = 1 G ∼ π θ ( ⋅ ∣ q ) [ 1 G ∑ i = 1 G ∑ t = 1 ∣ o i ∣ ∇ θ log π θ ( o i , t ∣ q , o i , < t ) A ^ i ] ] = E q ∼ p Q [ E { o i } i = 1 G ∼ π θ ( ⋅ ∣ q ) [ 1 G ∑ i = 1 G A ^ i ∇ θ log π θ ( o i ∣ q ) ] ] = E q ∼ p Q [ E { o i } i = 1 G ∼ π θ ( ⋅ ∣ q ) [ 1 G ∑ i = 1 G G G − 1 ( R ( q , o i ) − 1 G ∑ j = 1 G R ( q , o j ) ) ∇ θ log π θ ( o i ∣ q ) ] ] = E q ∼ p Q [ E { o i } i = 1 G ∼ π θ ( ⋅ ∣ q ) [ 1 G − 1 ∑ i = 1 G ( R ( q , o i ) − 1 G ∑ j = 1 G R ( q , o j ) ) ∇ θ log π θ ( o i ∣ q ) ] ] \begin{aligned}
\nabla_{\theta} J(\theta)
&= \mathbb{E}_{q \sim p_{\mathcal{Q}}}\Bigg[ \mathbb{E}_{\{o_{i}\}_{i=1}^{G} \sim \pi_{\theta}(\cdot \mid q)}\bigg[ \frac{1}{G} \sum_{i=1}^{G} \sum_{t=1}^{|o_{i}|} \nabla_{\theta} \log \pi_{\theta}(o_{i,t} \mid q, o_{i,<t}) \hat{A}_{i} \bigg]\Bigg]\\
&= \mathbb{E}_{q \sim p_{\mathcal{Q}}}\Bigg[ \mathbb{E}_{\{o_{i}\}_{i=1}^{G} \sim \pi_{\theta}(\cdot \mid q)}\bigg[ \frac{1}{G} \sum_{i=1}^{G} \hat{A}_{i} \nabla_{\theta} \log \pi_{\theta}(o_{i} \mid q) \bigg]\Bigg]\\
&= \mathbb{E}_{q \sim p_{\mathcal{Q}}}\Bigg[ \mathbb{E}_{\{o_{i}\}_{i=1}^{G} \sim \pi_{\theta}(\cdot \mid q)}\bigg[ \frac{1}{G} \sum_{i=1}^{G} \frac{G}{G-1} \bigg( R(q,o_{i}) - \frac{1}{G} \sum_{j=1}^{G} R(q,o_{j}) \bigg) \nabla_{\theta} \log \pi_{\theta}(o_{i} \mid q) \bigg]\Bigg]\\
&= \mathbb{E}_{q \sim p_{\mathcal{Q}}}\Bigg[ \mathbb{E}_{\{o_{i}\}_{i=1}^{G} \sim \pi_{\theta}(\cdot \mid q)}\bigg[ \frac{1}{G-1} \sum_{i=1}^{G} \bigg( R(q,o_{i}) - \frac{1}{G} \sum_{j=1}^{G} R(q,o_{j}) \bigg) \nabla_{\theta} \log \pi_{\theta}(o_{i} \mid q) \bigg]\Bigg]
\end{aligned}
∇ θ J ( θ ) = E q ∼ p Q [ E { o i } i = 1 G ∼ π θ ( ⋅ ∣ q ) [ G 1 i = 1 ∑ G t = 1 ∑ ∣ o i ∣ ∇ θ log π θ ( o i , t ∣ q , o i , < t ) A ^ i ] ] = E q ∼ p Q [ E { o i } i = 1 G ∼ π θ ( ⋅ ∣ q ) [ G 1 i = 1 ∑ G A ^ i ∇ θ log π θ ( o i ∣ q ) ] ] = E q ∼ p Q [ E { o i } i = 1 G ∼ π θ ( ⋅ ∣ q ) [ G 1 i = 1 ∑ G G − 1 G ( R ( q , o i ) − G 1 j = 1 ∑ G R ( q , o j ) ) ∇ θ log π θ ( o i ∣ q ) ] ] = E q ∼ p Q [ E { o i } i = 1 G ∼ π θ ( ⋅ ∣ q ) [ G − 1 1 i = 1 ∑ G ( R ( q , o i ) − G 1 j = 1 ∑ G R ( q , o j ) ) ∇ θ log π θ ( o i ∣ q ) ] ]
从第一个等式也可看出,RLOO 策略梯度估计的最小计算单元不是单个样本,而是整个 group。
GRPO 与 RLOO 都是同期思路类似的工作,为了保持全文符号的一致性,我们这里是用 group G G G
ReMax
ReMax 是 RLOO 的同期工作,动机也是为了丢弃 PPO 中的 value network,其奖励信号也是 response-level (a.k.a., trajectory-level)。与 RLOO 的差异主要体现在 baseline 的设计。
对于每个 prompt q ∼ p Q q \sim p_{\mathcal{Q}} q ∼ p Q π θ ( ⋅ ∣ q ) \pi_{\theta}(\cdot \mid q) π θ ( ⋅ ∣ q ) G G G { o i } i = 1 G \{o_{i}\}_{i=1}^{G} { o i } i = 1 G
随机序列:o ∼ π θ ( ⋅ ∣ q ) o \sim \pi_{\theta}(\cdot \mid q) o ∼ π θ ( ⋅ ∣ q )
贪婪序列:o max o_{\text{max}} o max o max , t = arg max w π θ ( w ∣ q , o max , < t ) o_{\text{max},t} = \arg\max_{w} \pi_{\theta}(w \mid q,o_{\text{max},<t}) o max , t = arg max w π θ ( w ∣ q , o max , < t )
ReMax baseline 定义为贪婪序列的回报(实际上也是奖励)R ( q , o max ) R(q,o_{\text{max}}) R ( q , o max ) o max o_{\text{max}} o max o o o
GRPO: Group Relative Policy Optimization
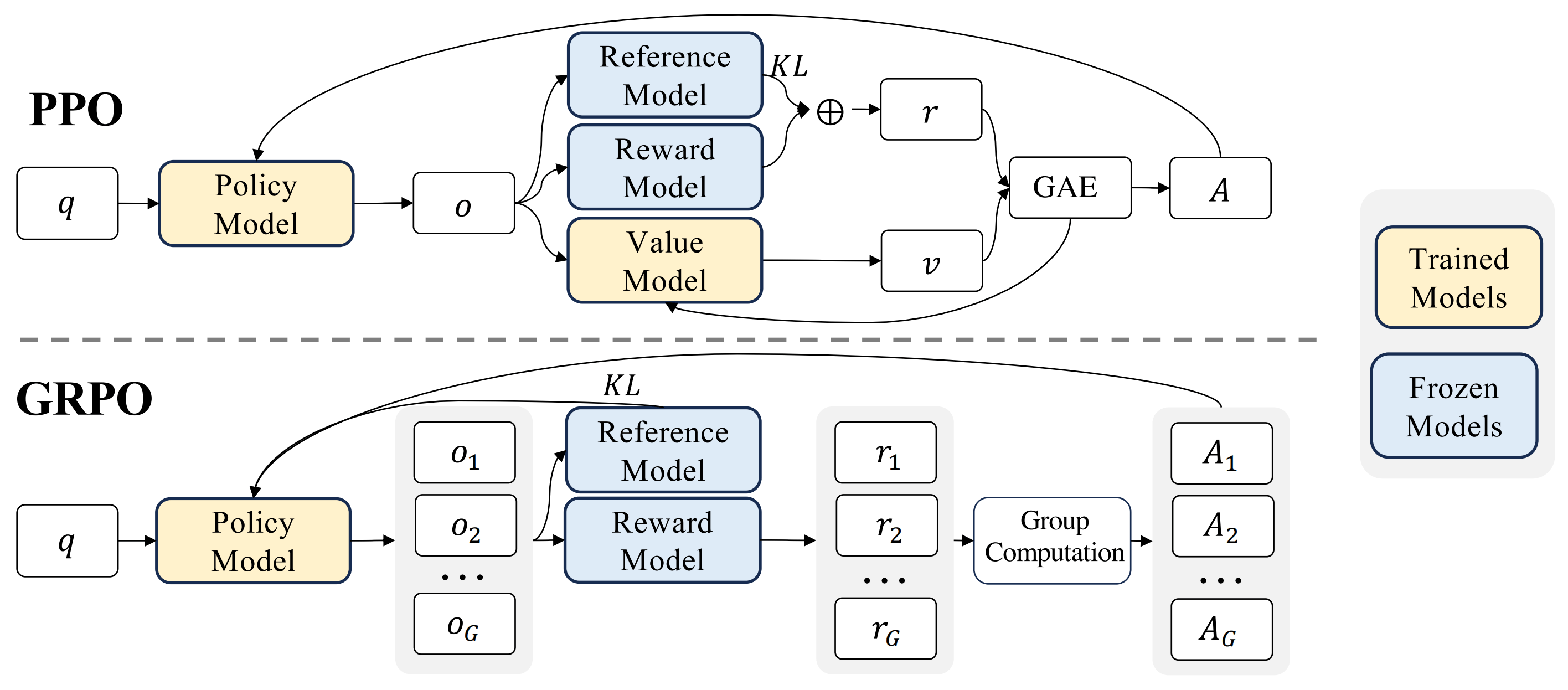
GRPO 也是 ReMax, RLOO 的同期工作,其基于 PPO 算法,如上图所示。其目标函数如下:
J ( θ ) = E q ∼ p Q , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min ( r i , t ( θ ) A ^ i , t , c l i p ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) − β D KL [ π θ ( ⋅ ∣ q ) ∥ π r e f ( ⋅ ∣ q ) ] } \begin{aligned}
J(\theta) &= \mathbb{E}_{q \sim p_{\mathcal{Q}},\{o_{i}\}_{i=1}^{G} \sim \pi_{\theta_{old}}(\cdot \mid q)} \\
& \frac{1}{G}\sum_{i=1}^{G} \frac{1}{|o_{i}|}\sum_{t=1}^{|o_{i}|} \bigg\{ \min\Big(
r_{i,t}(\theta) \hat{A}_{i,t},
\mathrm{clip}\big(r_{i,t}(\theta),1-\epsilon,1+\epsilon\big)\hat{A}_{i,t}
\Big) - \beta \mathbb{D}_{\text{KL}}\big[\pi_{\theta}(\cdot \mid q) \| \pi_{ref}(\cdot \mid q)\big] \bigg\}
\end{aligned}
J ( θ ) = E q ∼ p Q , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) G 1 i = 1 ∑ G ∣ o i ∣ 1 t = 1 ∑ ∣ o i ∣ { min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) − β D KL [ π θ ( ⋅ ∣ q ) ∥ π re f ( ⋅ ∣ q ) ] }
其中,policy ratio r i , t ( θ ) r_{i,t}(\theta) r i , t ( θ )
r i , t ( θ ) = π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) r_{i,t}(\theta) = \frac{\pi_{\theta}(o_{i,t} \mid q,o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t} \mid q,o_{i,<t})}
r i , t ( θ ) = π θ o l d ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t )
GRPO group 中 output o i o_{i} o i t t t o i , t o_{i,t} o i , t G ( q , o i , ≤ t ) G(q,o_{i,\le t}) G ( q , o i , ≤ t ) t t t
当奖励信号是 response-level 的结果监督时,G ( q , o i , ≤ t ) = G ( q , o i ) = R ~ ( q , o i ) G(q,o_{i,\le t}) = G(q,o_{i}) = \tilde{R}(q,o_{i}) G ( q , o i , ≤ t ) = G ( q , o i ) = R ~ ( q , o i )
A ^ i = G ( q , o i ) = R ~ ( q , o i ) = R ( q , o i ) − m e a n ( { R ( q , o 1 ) , … , R ( q , o G ) } ) s t d ( { R ( q , o 1 ) , … , R ( q , o G ) } ) \hat{A}_{i} = G(q,o_{i}) = \tilde{R}(q,o_{i}) = \frac{R(q,o_{i}) - \mathrm{mean}(\{ R(q,o_{1}),\ldots,R(q,o_{G}) \})}{\mathrm{std}(\{R(q,o_{1}),\ldots,R(q,o_{G})\})}
A ^ i = G ( q , o i ) = R ~ ( q , o i ) = std ({ R ( q , o 1 ) , … , R ( q , o G )}) R ( q , o i ) − mean ({ R ( q , o 1 ) , … , R ( q , o G )})
其中,R ~ ( q , o i ) \tilde{R}(q,o_{i}) R ~ ( q , o i ) A ^ i , t = A ^ i \hat{A}_{i,t}=\hat{A}_{i} A ^ i , t = A ^ i R ( q , o i ) = r ( q , o i ) R(q,o_{i})=r(q,o_{i}) R ( q , o i ) = r ( q , o i )
当奖励信号是 token-level 的过程监督时,reward 需要对所有 group 中各时间步进行归一化,则参与归一化计算的所有奖励信号可以表示为一个集合 R = { { R ( q , o 1 , ≤ 1 ) , … , R ( q , o 1 , ≤ ∣ o 1 ∣ ) } , … , { R ( q , o G , ≤ 1 ) , … , R ( q , o G , ≤ ∣ o G ∣ ) } } \mathbf{R} = \big\{\{R(q,o_{1,\le 1}),\ldots,R(q,o_{1,\le |o_{1}|})\},\ldots,\{R(q,o_{G,\le 1}),\ldots,R(q,o_{G,\le |o_{G}|})\}\big\} R = { { R ( q , o 1 , ≤ 1 ) , … , R ( q , o 1 , ≤ ∣ o 1 ∣ )} , … , { R ( q , o G , ≤ 1 ) , … , R ( q , o G , ≤ ∣ o G ∣ )} } ∑ i = 1 G ∣ o i ∣ \sum_{i=1}^{G}|o_{i}| ∑ i = 1 G ∣ o i ∣
R ~ ( q , o i , ≤ t ) = R ( q , o i , ≤ t ) − m e a n ( R ) s t d ( R ) \tilde{R}(q,o_{i,\le t}) = \frac{R(q,o_{i,\le t}) - \mathrm{mean}(\mathbf{R})}{\mathrm{std}(\mathbf{R})}
R ~ ( q , o i , ≤ t ) = std ( R ) R ( q , o i , ≤ t ) − mean ( R )
其中,即时奖励 R ( q , o i , ≤ t ) R(q,o_{i,\le t}) R ( q , o i , ≤ t ) R ( q , o i , ≤ t ) = r ( q , o i , ≤ t ) R(q,o_{i,\le t}) = r(q,o_{i,\le t}) R ( q , o i , ≤ t ) = r ( q , o i , ≤ t )
A ^ i , t = G ( q , o i , ≤ t ) = ∑ t ′ = t ∣ o i ∣ R ~ ( q , o i , ≤ t ′ ) \hat{A}_{i,t} = G(q,o_{i,\le t}) = \sum_{t^{\prime} = t}^{|o_{i}|} \tilde{R}(q,o_{i,\le t^{\prime}})
A ^ i , t = G ( q , o i , ≤ t ) = t ′ = t ∑ ∣ o i ∣ R ~ ( q , o i , ≤ t ′ )
除了优势近似外,还有几处与标准 PPO 的差异:
Length Normalization: 1 / ∣ o i ∣ 1/|o_{i}| 1/∣ o i ∣ o i o_{i} o i
KL Penalty: 直接将 KL 惩罚加入目标函数,而非采用 KL-shaped reward。因此,其目标函数的形式类似 PPO-Clip 与 PPO-Penalty 的统一
GRPO 目标函数中的 KL 散度使用 k 3 k_{3} k 3
D ^ KL [ π θ ( ⋅ ∣ q ) ∥ π r e f ( ⋅ ∣ q ) ] = π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − log π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − 1 \hat{\mathbb{D}}_{\text{KL}}\big[\pi_{\theta}(\cdot \mid q) \| \pi_{ref}(\cdot \mid q)\big] = \frac{\pi_{ref}(o_{i,t} \mid q,o_{i,<t})}{\pi_{\theta}(o_{i,t} \mid q,o_{i,<t})} - \log \frac{\pi_{ref}(o_{i,t} \mid q,o_{i,<t})}{\pi_{\theta}(o_{i,t} \mid q,o_{i,<t})} - 1
D ^ KL [ π θ ( ⋅ ∣ q ) ∥ π re f ( ⋅ ∣ q ) ] = π θ ( o i , t ∣ q , o i , < t ) π re f ( o i , t ∣ q , o i , < t ) − log π θ ( o i , t ∣ q , o i , < t ) π re f ( o i , t ∣ q , o i , < t ) − 1
对于 GRPO bias 的讨论,见 Dr. GRPO 一节。
Dr. GRPO: Group Relative Policy Optimization Done Right
此前,我们发现 GRPO 与 RLOO 的优势计算十分相似,Dr. GRPO 基于 GRPO 进行优化,并揭示了优化后的优势计算与 RLOO 的联系。首先,我们对比 GRPO,给出 Dr. GRPO 的目标函数:
J ( θ ) = E q ∼ p Q , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min ( r i , t ( θ ) A ^ i , t , c l i p ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) − β D KL [ π θ ( ⋅ ∣ q ) ∥ π r e f ( ⋅ ∣ q ) ] } \begin{aligned}
J(\theta) &= \mathbb{E}_{q \sim p_{\mathcal{Q}},\{o_{i}\}_{i=1}^{G} \sim \pi_{\theta_{old}}(\cdot \mid q)} \\
& \frac{1}{G}\sum_{i=1}^{G} {\color{red}\xcancel{\frac{1}{|o_{i}|}}} \sum_{t=1}^{|o_{i}|} \bigg\{ \min\Big(
r_{i,t}(\theta) \hat{A}_{i,t},
\mathrm{clip}\big(r_{i,t}(\theta),1-\epsilon,1+\epsilon\big)\hat{A}_{i,t}
\Big) {\color{red}\xcancel{- \beta \mathbb{D}_{\text{KL}}\big[\pi_{\theta}(\cdot \mid q) \| \pi_{ref}(\cdot \mid q)\big]}} \bigg\}
\end{aligned}
J ( θ ) = E q ∼ p Q , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) G 1 i = 1 ∑ G ∣ o i ∣ 1 t = 1 ∑ ∣ o i ∣ { min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) − β D KL [ π θ ( ⋅ ∣ q ) ∥ π re f ( ⋅ ∣ q ) ] }
其中
A ^ i = R ( q , o i ) − m e a n ( { R ( q , o 1 ) , … , R ( q , o G ) } ) s t d ( { R ( q , o 1 ) , … , R ( q , o G ) } ) \hat{A}_{i} = \frac{R(q,o_{i}) - \mathrm{mean}(\{ R(q,o_{1}),\ldots,R(q,o_{G}) \})}{\color{red}\xcancel{\mathrm{std}(\{R(q,o_{1}),\ldots,R(q,o_{G})\})}}
A ^ i = std ({ R ( q , o 1 ) , … , R ( q , o G )}) R ( q , o i ) − mean ({ R ( q , o 1 ) , … , R ( q , o G )})
为了简化分析,我们不妨假设只有结果奖励信号,即:A ^ i , t = A ^ i \hat{A}_{i,t} = \hat{A}_{i} A ^ i , t = A ^ i
对比 GRPO 发现,Dr. GRPO 移除了目标函数中的 KL 惩罚,更核心的是,移除了 1 / ∣ o i ∣ \color{red}1/|o_{i}| 1/∣ o i ∣ s t d ( { R ( q , o 1 ) , … , R ( q , o G ) } ) \color{red}\mathrm{std}(\{R(q,o_{1}),\ldots,R(q,o_{G})\}) std ({ R ( q , o 1 ) , … , R ( q , o G )})
Response-level length bias : 源于 1 / ∣ o i ∣ \color{red}1/|o_{i}| 1/∣ o i ∣
当 A ^ i > 0 \hat{A}_{i} > 0 A ^ i > 0 o i o_{i} o i
当 A ^ i < 0 \hat{A}_{i} < 0 A ^ i < 0 o i o_{i} o i
Question-level difficulty bias : 源于 s t d ( { R ( q , o 1 ) , … , R ( q , o G ) } ) \color{red}\mathrm{std}(\{R(q,o_{1}),\ldots,R(q,o_{G})\}) std ({ R ( q , o 1 ) , … , R ( q , o G )}) 1 1 1 0 0 0
最后,证明 Dr. GRPO 优势的无偏性,从 RLOO 优势出发:
A ^ i RLOO = G G − 1 ( R ( q , o i ) − 1 G ∑ j = 1 G R ( q , o j ) ) = G G − 1 A ^ i Dr.GRPO \begin{aligned}
\hat{A}_{i}^{\text{RLOO}}
&= \frac{G}{G-1} \bigg( R(q,o_{i}) - \frac{1}{G} \sum_{j=1}^{G} R(q,o_{j}) \bigg)\\
&= \frac{G}{G-1} \hat{A}_{i}^{\text{Dr.GRPO}}
\end{aligned}
A ^ i RLOO = G − 1 G ( R ( q , o i ) − G 1 j = 1 ∑ G R ( q , o j ) ) = G − 1 G A ^ i Dr.GRPO
由于 RLOO 优势对策略梯度的近似是无偏的,我们只需证明 Dr. GRPO 与 RLOO 优势等价即可。我们发现,当 group size G → ∞ G \to \infty G → ∞ A ^ i Dr.GRPO → A ^ i RLOO \hat{A}_{i}^{\text{Dr.GRPO}} \to \hat{A}_{i}^{\text{RLOO}} A ^ i Dr.GRPO → A ^ i RLOO G / ( G − 1 ) G/(G-1) G / ( G − 1 )
REINFORCE++
如上图所示,REINFORCE++ 基于 GRPO 进行改进,核心思想在于对优势函数使用 batch normalization,目标函数仍然是 PPO loss。其奖励信号与 PPO 一致,采用 token-level KL-shaped reward,表示如下:
R ( q , o ≤ t ) = I ( o t = [ EOS ] ) r ( q , o ) − β KL t R(q,o_{\le t}) = \mathbf{I}(o_{t} = [\text{EOS}])r(q,o) - \beta \text{KL}_{t}
R ( q , o ≤ t ) = I ( o t = [ EOS ]) r ( q , o ) − β KL t
其中,KL t \text{KL}_{t} KL t r ( q , o ) r(q,o) r ( q , o ) [ q , o ] [q,o] [ q , o ] R ( q , o ≤ t ) = r ( q , o ≤ t ) R(q,o_{\le t}) = r(q,o_{\le t}) R ( q , o ≤ t ) = r ( q , o ≤ t ) k 1 k_{1} k 1
KL t = log π θ o l d ( o t ∣ q , o < t ) π r e f ( o t ∣ q , o < t ) \text{KL}_{t} = \log \frac{\pi_{\theta_{old}}(o_{t} \mid q,o_{<t})}{\pi_{ref}(o_{t} \mid q,o_{<t})}
KL t = log π re f ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t )
标准 REINFORCE++ 移除了 GRPO 中的 group,沿用 PPO 的算法步骤:
从 prompt dataset p Q p_{\mathcal{Q}} p Q { q ( n ) } n = 1 N ∼ p Q \{q^{(n)}\}_{n=1}^{N} \sim p_{\mathcal{Q}} { q ( n ) } n = 1 N ∼ p Q
对于每个 prompt q ( n ) q^{(n)} q ( n ) o ( n ) ∼ π θ o l d ( ⋅ ∣ q ( n ) ) o^{(n)} \sim \pi_{\theta_{old}}(\cdot \mid q^{(n)}) o ( n ) ∼ π θ o l d ( ⋅ ∣ q ( n ) )
为 batch 中每个 output o ( n ) o^{(n)} o ( n ) t t t R ( q ( n ) , o ≤ t ( n ) ) R(q^{(n)},o_{\le t}^{(n)}) R ( q ( n ) , o ≤ t ( n ) ) A ^ t ( n ) \hat{A}_{t}^{(n)} A ^ t ( n )
其中,优势使用 global batch normalization 进行计算。类似 GRPO,我们先将参与归一化计算的所有奖励信号表示为一个集合 R = { { R ( q ( 1 ) , o ≤ 1 ( 1 ) ) , … , R ( q ( 1 ) , o ≤ ∣ o ( 1 ) ∣ ( 1 ) ) } , … , { R ( q ( N ) , o ≤ 1 ( N ) ) , … , R ( q ( N ) , o ≤ ∣ o ( N ) ∣ ( N ) ) } } \mathbf{R} = \big\{\{R(q^{(1)},o_{\le 1}^{(1)}),\ldots,R(q^{(1)},o_{\le |o^{(1)}|}^{(1)})\},\ldots,\{R(q^{(N)},o_{\le 1}^{(N)}),\ldots,R(q^{(N)},o_{\le |o^{(N)}|}^{(N)})\}\big\} R = { { R ( q ( 1 ) , o ≤ 1 ( 1 ) ) , … , R ( q ( 1 ) , o ≤ ∣ o ( 1 ) ∣ ( 1 ) )} , … , { R ( q ( N ) , o ≤ 1 ( N ) ) , … , R ( q ( N ) , o ≤ ∣ o ( N ) ∣ ( N ) )} } ∑ n = 1 N ∣ o ( n ) ∣ \sum_{n=1}^{N}|o^{(n)}| ∑ n = 1 N ∣ o ( n ) ∣
A ^ t ( n ) = R ( q ( n ) , o ≤ t ( n ) ) − m e a n ( R ) s t d ( R ) \hat{A}_{t}^{(n)} = \frac{R(q^{(n)},o_{\le t}^{(n)}) - \mathrm{mean}(\mathbf{R})}{\mathrm{std}(\mathbf{R})}
A ^ t ( n ) = std ( R ) R ( q ( n ) , o ≤ t ( n ) ) − mean ( R )
这里也看出与 GRPO 的显著区别,REINFORCE++ 沿用 PPO,为每个 prompt 仅采样一个 response,而 GRPO 是采样一组 response,这也造成了 normalization 方式的差异。
这里计算优势时,使用的仍然是即时奖励,而非回报。当 GRPO 使用 token-level reward 时,优势使用回报近似,而非即时奖励。
实际上,为了支持 multi-response 的场景,REINFORCE+±baseline 这一变体被提出。首先,为 batch 所有样本计算各自的 group normalized advantage A ^ i , t ( n ) \hat{A}_{i,t}^{(n)} A ^ i , t ( n ) ( n ) (n) ( n )
A ^ i , t = R ( q , o i , ≤ t ) − m e a n ( { { R ( q , o 1 , ≤ 1 ) , … , R ( q , o 1 , ≤ ∣ o 1 ∣ ) } , … , { R ( q , o G , ≤ 1 ) , … , R ( q , o G , ≤ ∣ o G ∣ ) } } ) \hat{A}_{i,t} = R(q,o_{i,\le t}) - \mathrm{mean}\big(\big\{\{R(q,o_{1,\le 1}),\ldots,R(q,o_{1,\le |o_{1}|})\},\ldots,\{R(q,o_{G,\le 1}),\ldots,R(q,o_{G,\le |o_{G}|})\}\big\}\big)
A ^ i , t = R ( q , o i , ≤ t ) − mean ( { { R ( q , o 1 , ≤ 1 ) , … , R ( q , o 1 , ≤ ∣ o 1 ∣ )} , … , { R ( q , o G , ≤ 1 ) , … , R ( q , o G , ≤ ∣ o G ∣ )} } )
类似 Dr. GRPO,这里的 group normalization 并不会除以标准差。最后,与标准 REINFORCE++ 一致,进一步计算 global batch normalized advantage。这里不再给出具体计算公式,因为符号表示较复杂。需要注意的是,参与均值与标准差运算的样本数量为 ∑ n = 1 N ∑ i = 1 G ∣ o i ( n ) ∣ \sum_{n=1}^{N} \sum_{i=1}^{G} |o_{i}^{(n)}| ∑ n = 1 N ∑ i = 1 G ∣ o i ( n ) ∣
DAPO: Decouple Clip and Dynamic sAmpling Policy Optimization
DAPO 基于 GRPO 算法,针对 long-CoT RL 场景进行改进。对比 GRPO,其目标函数如下:
J ( θ ) = E ( q , a ) ∼ p Q , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) 1 ∑ i = 1 G ∣ o i ∣ 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min ( r i , t ( θ ) A ^ i , t , c l i p ( r i , t ( θ ) , 1 − ϵ low , 1 + ϵ high ) A ^ i , t ) − β D KL [ π θ ( ⋅ ∣ q ) ∥ π r e f ( ⋅ ∣ q ) ] } s.t. 0 < ∣ { o i ∣ i s _ e q u i v a l e n t ( a , o i ) } ∣ < G \begin{aligned}
J(\theta) &= \mathbb{E}_{(q,a) \sim p_{\mathcal{Q}},\{o_{i}\}_{i=1}^{G} \sim \pi_{\theta_{old}}(\cdot \mid q)} \\
& {\color{red}\frac{1}{\sum_{i=1}^{G}|o_{i}|} \xcancel{\frac{1}{G}}}\sum_{i=1}^{G} {\color{red}\xcancel{\frac{1}{|o_{i}|}}} \sum_{t=1}^{|o_{i}|} \bigg\{ \min\Big(
r_{i,t}(\theta) \hat{A}_{i,t},
\mathrm{clip}\big(r_{i,t}(\theta),1-\epsilon_{\text{low}},1+\epsilon_{\text{high}}\big)\hat{A}_{i,t}
\Big) {\color{red}\xcancel{- \beta \mathbb{D}_{\text{KL}}\big[\pi_{\theta}(\cdot \mid q) \| \pi_{ref}(\cdot \mid q)\big]}} \bigg\} \\
& {\color{red}\text{s.t.}\quad 0 < \Big| \{ o_{i} \mid \mathrm{is\_equivalent}(a,o_{i}) \} \Big| < G}
\end{aligned}
J ( θ ) = E ( q , a ) ∼ p Q , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) ∑ i = 1 G ∣ o i ∣ 1 G 1 i = 1 ∑ G ∣ o i ∣ 1 t = 1 ∑ ∣ o i ∣ { min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ low , 1 + ϵ high ) A ^ i , t ) − β D KL [ π θ ( ⋅ ∣ q ) ∥ π re f ( ⋅ ∣ q ) ] } s.t. 0 < { o i ∣ is_equivalent ( a , o i )} < G
其中,( q , a ) ∼ p Q (q,a) \sim p_{\mathcal{Q}} ( q , a ) ∼ p Q p Q p_{\mathcal{Q}} p Q
RLHF 中,我们的目标是在不偏离初始模型太远的情况下,微调模型使之与人类偏好对齐
Long-CoT Reasoning RL 中,对于一个复杂的数学或逻辑问题,初始模型可能根本不知道如何解答。我们希望鼓励模型探索,生成 long-CoT,这个过程中,模型的概率分布会发生较大变化,因此不需要 KL 惩罚的限制
剩余的改进归纳为四点:
Techniques
Goals
Formulation
Clip-Higher
鼓励探索,避免熵坍缩
ϵ low \epsilon_{\text{low}} ϵ low ϵ high \epsilon_{\text{high}} ϵ high
Dynamic Sampling
持续提供有效梯度,加快收敛
s.t. 0 < ∣ { o i ∣ i s _ e q u i v a l e n t ( a , o i ) } ∣ < G \text{s.t.}\quad 0 < \vert \{ o_{i} \mid \mathrm{is\_equivalent}(a,o_{i}) \} \vert < G s.t. 0 < ∣ { o i ∣ is_equivalent ( a , o i )} ∣ < G
Token-Level Policy Gradient Loss
避免较长序列梯度的稀释
1 / ∑ i = 1 G ∣ o i ∣ 1 / \sum_{i=1}^{G}\vert o_{i} \vert 1/ ∑ i = 1 G ∣ o i ∣
Overlong Reward Shaping
降低奖励噪音
R length R_{\text{length}} R length
在正式解读前,先明确其奖励信号。为了避免 reward hacking 问题,直接使用 rule-based verifier 而非 reward model。规则奖励公式如下:
R rule ( y ^ , y ) = { 1 , i s _ e q u i v a l e n t ( y ^ , y ) − 1 , otherwise R_{\text{rule}}(\hat{y},y) = \begin{cases}
1, & \mathrm{is\_equivalent}(\hat{y},y) \\
-1, & \text{otherwise}
\end{cases}
R rule ( y ^ , y ) = { 1 , − 1 , is_equivalent ( y ^ , y ) otherwise
其中,y y y y ^ \hat{y} y ^
在 Overlong Reward Shaping 中,还会引入 R length ( o i ) R_{\text{length}}(o_{i}) R length ( o i ) R ( q , a , o i ) = R rule ( a , o i ) + R length ( o i ) R(q,a,o_{i}) = R_{\text{rule}}(a,o_{i}) + R_{\text{length}}(o_{i}) R ( q , a , o i ) = R rule ( a , o i ) + R length ( o i )
A ^ i , t = A ^ i = R ( q , a , o i ) − m e a n ( { R ( q , a , o j ) } j = 1 G ) s t d ( { R ( q , a , o j ) } j = 1 G ) \hat{A}_{i,t} = \hat{A}_{i} = \frac{R(q,a,o_{i}) - \mathrm{mean}(\{R(q,a,o_{j})\}_{j=1}^{G})}{\mathrm{std}(\{R(q,a,o_{j})\}_{j=1}^{G})}
A ^ i , t = A ^ i = std ({ R ( q , a , o j ) } j = 1 G ) R ( q , a , o i ) − mean ({ R ( q , a , o j ) } j = 1 G )
Clip-Higher
Clip-Higher 针对熵坍缩问题,通过解耦 clip 上下界 ϵ low \epsilon_{\text{low}} ϵ low ϵ high \epsilon_{\text{high}} ϵ high r t ( θ ) r_{t}(\theta) r t ( θ ) [ 1 − ϵ , 1 + ϵ ] [1-\epsilon,1+\epsilon] [ 1 − ϵ , 1 + ϵ ] ϵ = 0.2 \epsilon=0.2 ϵ = 0.2 ϵ low = 0.2 \epsilon_{\text{low}} = 0.2 ϵ low = 0.2 ϵ high = 0.28 \epsilon_{\text{high}} = 0.28 ϵ high = 0.28
Dynamic Sampling
在 GRPO 中,当一个 question q q q G G G + 1 +1 + 1 − 1 -1 − 1 + 1 +1 + 1 − 1 -1 − 1 G G G 0 0 0
Dynamic Sampling 的核心思想是:只用能产生有效梯度的样本进行训练。DAPO 通过在目标函数中添加一个约束条件来实现:
s.t. 0 < ∣ { o i ∣ i s _ e q u i v a l e n t ( a , o i ) } ∣ < G \text{s.t.}\quad 0 < | \{ o_{i} \mid \mathrm{is\_equivalent}(a,o_{i}) \} | < G
s.t. 0 < ∣ { o i ∣ is_equivalent ( a , o i )} ∣ < G
这个约束的含义是,对于每个 question q q q G G G ∣ { o i ∣ i s _ e q u i v a l e n t ( a , o i ) } ∣ = G | \{ o_{i} \mid \mathrm{is\_equivalent}(a,o_{i}) \} | = G ∣ { o i ∣ is_equivalent ( a , o i )} ∣ = G { o i ∣ i s _ e q u i v a l e n t ( a , o i ) } ∣ = 0 \{ o_{i} \mid \mathrm{is\_equivalent}(a,o_{i}) \} | = 0 { o i ∣ is_equivalent ( a , o i )} ∣ = 0
Token-Level Policy Gradient Loss
原始的 GRPO 算法采用 sample-level loss。它首先计算每个 response 内所有 token 损失均值,再计算 batch 内所有 response 损失均值。在这种权重下,每个样本,不论长短,对最终总损失的贡献是均等的。在 long-CoT 场景中,存在两个问题:
长样本中每个 token 的权重被稀释了,使得模型难以从高质量的长推理过程中充分学习其内在模式。
过长样本中常常包含无意义的重复与胡言乱语的 token。由于权重被稀释,sample-level loss 无法有效惩罚这些低质量模式,导致模型生成熵和响应长度不受控制地 " 野蛮生长 "
与 GRPO 先对 response 求均值,再对 batch 求均值不同,DAPO 将 batch 内所有 response 的所有 token loss 直接求均值。具体来说,将目标函数中的 1 / ∣ o i ∣ 1/|o_{i}| 1/∣ o i ∣ 1 / ∑ i = 1 G ∣ o i ∣ 1/\sum_{i=1}^{G}|o_{i}| 1/ ∑ i = 1 G ∣ o i ∣
Overlong Reward Shaping
在 RL-tuning 中,通常会设定一个最大生成长度,超出长度的 response 会被截断。然而,一个可能包含完全正确推理过程的 response,因为尚未出现正确答案(e.g., \boxed{})而被截断,导致规则奖励为 − 1 -1 − 1
DAPO 探索了两种途径,一种是 Overlong Filtering,直接将被截断的样本的损失 mask 掉,使它们不参与梯度计算,已经能稳定训练并提升性能。另一种是 Soft Overlong Punishment,设计一个长度惩罚如下:
R length ( y ) = { 0 , ∣ y ∣ ≤ L max − L cache Case 1: Safe Zone ( L max − L cache ) − ∣ y ∣ L cache , L max − L cache < ∣ y ∣ ≤ L max Case 2: Soft Punishment Buffer − 1 , ∣ y ∣ > L max Case 3: Hard Punishment Zone R_{\text{length}}(y) = \begin{cases}
0, & |y| \le L_{\text{max}} - L_{\text{cache}} & \text{Case 1: Safe Zone} \\
\frac{(L_{\text{max}} - L_{\text{cache}}) - |y|}{L_{\text{cache}}}, & L_{\text{max}} - L_{\text{cache}} < |y| \le L_{\text{max}} & \text{Case 2: Soft Punishment Buffer} \\
-1, & |y| > L_{\text{max}} & \text{Case 3: Hard Punishment Zone}
\end{cases}
R length ( y ) = ⎩ ⎨ ⎧ 0 , L cache ( L max − L cache ) − ∣ y ∣ , − 1 , ∣ y ∣ ≤ L max − L cache L max − L cache < ∣ y ∣ ≤ L max ∣ y ∣ > L max Case 1: Safe Zone Case 2: Soft Punishment Buffer Case 3: Hard Punishment Zone
其中:
∣ y ∣ |y| ∣ y ∣ y y y L max L_{\text{max}} L max L cache L_{\text{cache}} L cache
注意,这里 L max L_{\text{max}} L max max_tokens。实际上,该论文实验设定 L max = 16 , 384 L_{\text{max}}=16,384 L max = 16 , 384 L cache = 4 , 096 L_{\text{cache}}=4,096 L cache = 4 , 096 L max + L cache = 20 , 480 L_{\text{max}} + L_{\text{cache}} = 20,480 L max + L cache = 20 , 480
此时,我们来详细解读长度惩罚函数的三个阶段:
第一阶段:安全区(0 < ∣ y ∣ ≤ 12 , 288 0 < |y| \le 12,288 0 < ∣ y ∣ ≤ 12 , 288
第二阶段:软惩罚区(12 , 288 < ∣ y ∣ ≤ 16 , 384 12,288 < |y| \le 16,384 12 , 288 < ∣ y ∣ ≤ 16 , 384 R length = 0 R_{\text{length}} = 0 R length = 0 L max L_{\text{max}} L max − 1 -1 − 1
第三阶段:硬惩罚区(16 , 384 < ∣ y ∣ ≤ 20 , 480 16,384 < |y| \le 20,480 16 , 384 < ∣ y ∣ ≤ 20 , 480 L max L_{\text{max}} L max − 1 -1 − 1
该长度惩罚会直接添加到规则奖励中,最终的奖励函数为 R ( q , a , o i ) = R rule ( a , o i ) + R length ( o i ) R(q,a,o_{i}) = R_{\text{rule}}(a,o_{i}) + R_{\text{length}}(o_{i}) R ( q , a , o i ) = R rule ( a , o i ) + R length ( o i ) ∣ y ∣ > 20 , 480 |y| >20,480 ∣ y ∣ > 20 , 480 − 1 -1 − 1 − 1 -1 − 1
CISPO: Clipped IS-weight Policy Optimization
MiniMax-M1 技术报告中提出了 CISPO 算法,该算法主要解决 PPO/GRPO 中存在的 token clipping 问题。具体来说,一些与反思行为有关的 token (e.g., “However”, “Recheck”, “Wait”, “Aha”) 会充当推理路径中的分叉,但它们的概率通常在 base model 中很稀有。而在策略更新时,这些 token 会表现出较高的 r i , t ( θ ) r_{i,t}(\theta) r i , t ( θ )
接下来,具体距离来分析这一问题。PPO/GRPO 目标函数中核心项如下:
min ( r i , t ( θ ) A ^ i , t , c l i p ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) \min\Big(
r_{i,t}(\theta) \hat{A}_{i,t},
\mathrm{clip}\big(r_{i,t}(\theta),1-\epsilon,1+\epsilon\big)\hat{A}_{i,t}
\Big)
min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t )
第一次 on-policy 梯度更新时,由于 π θ = π θ o l d \pi_{\theta}=\pi_{\theta_{old}} π θ = π θ o l d r i , t ( θ ) = 1 r_{i,t}(\theta)=1 r i , t ( θ ) = 1 r i , t ( θ ) = 2 r_{i,t}(\theta)=2 r i , t ( θ ) = 2 ϵ = 0.2 \epsilon=0.2 ϵ = 0.2 1 + ϵ = 1.2 1+\epsilon=1.2 1 + ϵ = 1.2 c l i p \mathrm{clip} clip r i , t ( θ ) r_{i,t}(\theta) r i , t ( θ ) 0 0 0 r i , t ( θ ) r_{i,t}(\theta) r i , t ( θ ) θ \theta θ 0 0 0 r i , t ( θ ) r_{i,t}(\theta) r i , t ( θ ) r i , t ( θ ) = 0.5 r_{i,t}(\theta)=0.5 r i , t ( θ ) = 0.5 1 − ϵ = 0.8 1-\epsilon=0.8 1 − ϵ = 0.8 θ \theta θ ϵ low \epsilon_{\text{low}} ϵ low ϵ high \epsilon_{\text{high}} ϵ high
为了解决这一问题,CISPO 不对 token 更新本身进行裁剪,而是直接裁剪 IS weight (a.k.a., policy ratio) r i , t ( θ ) r_{i,t}(\theta) r i , t ( θ ) r i , t ( θ ) r_{i,t}(\theta) r i , t ( θ )
J ( θ ) = E ( q , a ) ∼ p Q , o ∼ π θ o l d ( ⋅ ∣ q ) [ 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ s g ( r i , t ( θ ) ) A ^ i , t log π θ ( o i , t ∣ q , o i , < t ) ] J(\theta) = \mathbb{E}_{(q,a) \sim p_{\mathcal{Q}},o \sim \pi_{\theta_{old}}(\cdot \mid q)}\Bigg[ \frac{1}{|o_{i}|}\sum_{t=1}^{|o_{i}|} \mathrm{sg}(r_{i,t}(\theta)) \hat{A}_{i,t} \log \pi_{\theta}(o_{i,t} \mid q,o_{i,<t}) \Bigg]
J ( θ ) = E ( q , a ) ∼ p Q , o ∼ π θ o l d ( ⋅ ∣ q ) [ ∣ o i ∣ 1 t = 1 ∑ ∣ o i ∣ sg ( r i , t ( θ )) A ^ i , t log π θ ( o i , t ∣ q , o i , < t ) ]
其中,s g ( ⋅ ) \mathrm{sg}(\cdot) sg ( ⋅ ) log π θ \log \pi_{\theta} log π θ A ^ i , t \hat{A}_{i,t} A ^ i , t 1 / ∣ o i ∣ 1/|o_{i}| 1/∣ o i ∣
接下来,基于 GRPO,给出 CISPO 算法的目标函数:
J ( θ ) = E ( q , a ) ∼ p Q , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) [ 1 ∑ i = 1 G ∣ o i ∣ ∑ i = 1 G ∑ t = 1 ∣ o i ∣ s g ( r ^ i , t ( θ ) ) A ^ i , t log π θ ( o i , t ∣ q , o i , < t ) ] J(\theta) = \mathbb{E}_{(q,a) \sim p_{\mathcal{Q}},\{o_{i}\}_{i=1}^{G} \sim \pi_{\theta_{old}}(\cdot \mid q)}\Bigg[ {\color{red}\frac{1}{\sum_{i=1}^{G}|o_{i}|}} \sum_{i=1}^{G} \sum_{t=1}^{|o_{i}|} \mathrm{sg}({\color{red}\hat{r}_{i,t}(\theta)}) \hat{A}_{i,t} \log \pi_{\theta}(o_{i,t} \mid q,o_{i,<t}) \Bigg]
J ( θ ) = E ( q , a ) ∼ p Q , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) [ ∑ i = 1 G ∣ o i ∣ 1 i = 1 ∑ G t = 1 ∑ ∣ o i ∣ sg ( r ^ i , t ( θ ) ) A ^ i , t log π θ ( o i , t ∣ q , o i , < t ) ]
其中,优势近似 A ^ i , t \hat{A}_{i,t} A ^ i , t r ^ i , t ( θ ) \hat{r}_{i,t}(\theta) r ^ i , t ( θ )
r ^ i , t ( θ ) = c l i p ( r i , t ( θ ) , 1 − ϵ low IS , 1 − ϵ high IS ) \hat{r}_{i,t}(\theta) = \mathrm{clip}(r_{i,t}(\theta),1-\epsilon_{\text{low}}^{\text{IS}},1-\epsilon_{\text{high}}^{\text{IS}})
r ^ i , t ( θ ) = clip ( r i , t ( θ ) , 1 − ϵ low IS , 1 − ϵ high IS )
在实验中,不设置 IS weight 的下限,即将 ϵ low IS \epsilon_{\text{low}}^{\text{IS}} ϵ low IS ϵ high IS \epsilon_{\text{high}}^{\text{IS}} ϵ high IS
此外,CISPO 也利用了 DAPO 的 dynamic sampling 与 length penalty 技术,同时移除了 KL 惩罚。
最后,通过在目标函数中引入一个 token-wise mask M i , t M_{i,t} M i , t
J ( θ ) = E ( q , a ) ∼ p Q , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) [ 1 ∑ i = 1 G ∣ o i ∣ ∑ i = 1 G ∑ t = 1 ∣ o i ∣ s g ( r ^ i , t ( θ ) ) A ^ i , t log π θ ( o i , t ∣ q , o i , < t ) M i , t ] J(\theta) = \mathbb{E}_{(q,a) \sim p_{\mathcal{Q}},\{o_{i}\}_{i=1}^{G} \sim \pi_{\theta_{old}}(\cdot \mid q)}\Bigg[ \frac{1}{\sum_{i=1}^{G}|o_{i}|} \sum_{i=1}^{G} \sum_{t=1}^{|o_{i}|} \mathrm{sg}(\hat{r}_{i,t}(\theta)) \hat{A}_{i,t} \log \pi_{\theta}(o_{i,t} \mid q,o_{i,<t}) {\color{red}M_{i,t}} \Bigg]
J ( θ ) = E ( q , a ) ∼ p Q , { o i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) [ ∑ i = 1 G ∣ o i ∣ 1 i = 1 ∑ G t = 1 ∑ ∣ o i ∣ sg ( r ^ i , t ( θ )) A ^ i , t log π θ ( o i , t ∣ q , o i , < t ) M i , t ]
其中,mask M i , t M_{i,t} M i , t
M i , t = { 0 , A ^ i , t > 0 and r i , t ( θ ) > 1 + ϵ high 0 , A ^ i , t < 0 and r i , t ( θ ) < 1 + ϵ low 1 , otherwise M_{i,t} = \begin{cases}
0, & \hat{A}_{i,t} > 0 \text{ and } r_{i,t}(\theta) > 1 + \epsilon_{\text{high}} \\
0, & \hat{A}_{i,t} < 0 \text{ and } r_{i,t}(\theta) < 1 + \epsilon_{\text{low}} \\
1, & \text{otherwise}
\end{cases}
M i , t = ⎩ ⎨ ⎧ 0 , 0 , 1 , A ^ i , t > 0 and r i , t ( θ ) > 1 + ϵ high A ^ i , t < 0 and r i , t ( θ ) < 1 + ϵ low otherwise
观察上式可知,M i , t = 0 M_{i,t} = 0 M i , t = 0
min ( r i , t ( θ ) A ^ i , t , c l i p ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) \min\Big(
r_{i,t}(\theta) \hat{A}_{i,t},
\mathrm{clip}\big(r_{i,t}(\theta),1-\epsilon,1+\epsilon\big)\hat{A}_{i,t}
\Big)
min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t )
而当 M i , t = 1 M_{i,t} = 1 M i , t = 1
总结 PPO/GRPO 与 CISPO token-level 梯度信号控制的思路对比:前者可以概括为,当某个 token r i , t ( θ ) r_{i,t}(\theta) r i , t ( θ ) r i , t ( θ ) r_{i,t}(\theta) r i , t ( θ )
Reference
对于本文的符号使用,主要参考 Dr. GRPO 的论文,后面会列出。
对于 RL4LLM 进展梳理的文章已经有很多,笔者写作时都有参考:
对于各个算法的论文原文及论文解读,列举如下:
PPO
RLOO
ReMax
GRPO
Dr. GRPO
REINFORCE++
DAPO
CISPO