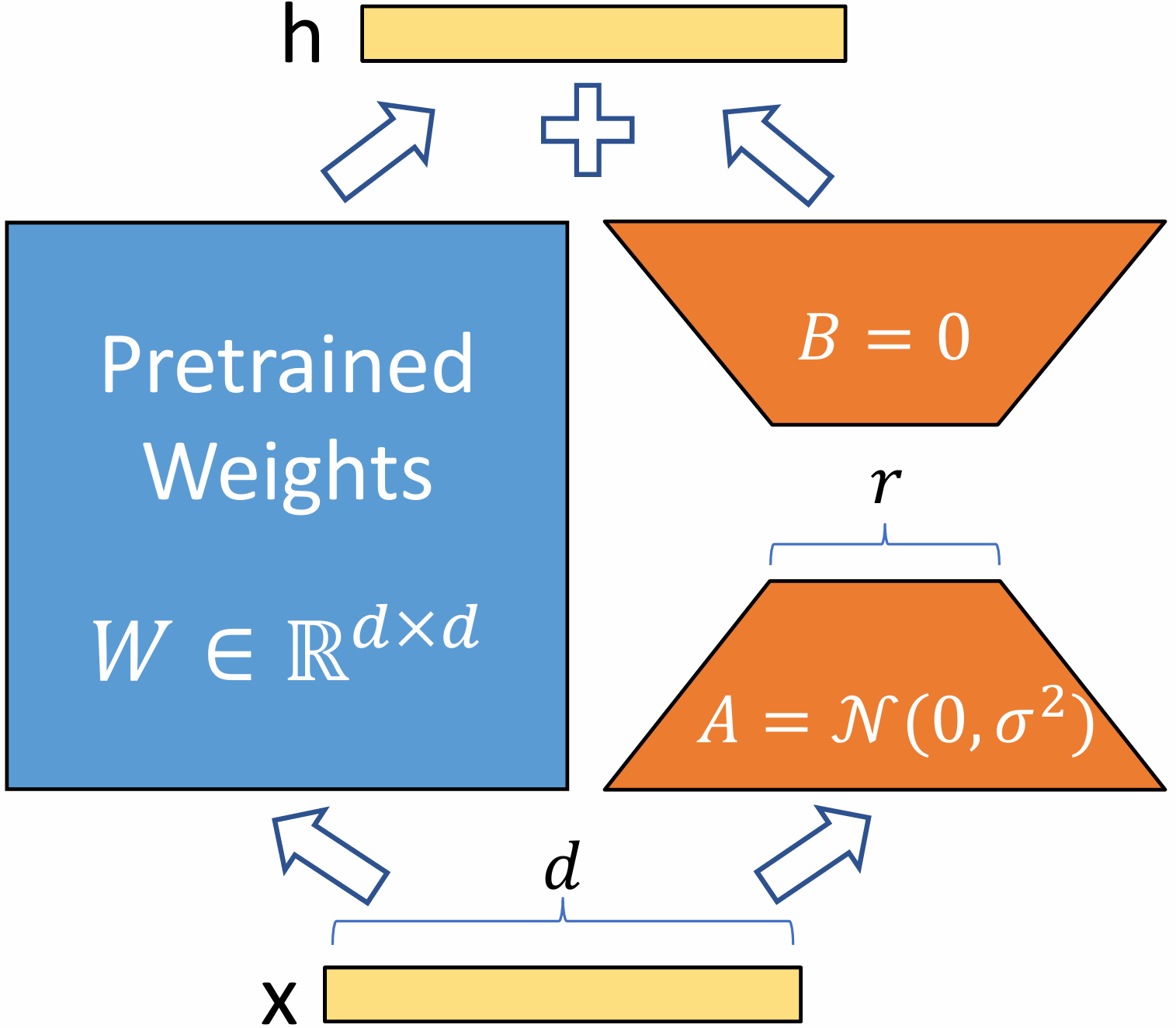
LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning (PEFT) technique designed to reduce the number of trainable parameters in LLMs while maintaining high performance. It achieves this by decomposing weight updates into low-rank matrices, significantly reducing memory and computational costs.
Motivation: Intrinsic Dimension Hypothesis
The Intrinsic Dimension Hypothesis states that high-dimensional models actually lie on a much lower-dimensional subspace. Similarly, LoRA hypothesizes finetuning a LLM requires only modifying a small subset of parameters or searching within a low-rank space.
Approach: Low-Rank Decomposition
Standard Full Fine-Tuning
Given a pretrained LLM, consider a weight matrix W∈Rdin×dout. FFT (full fine-tuning) updates this matrix as:
W←W+ΔW
where ΔW is the update learned through gradient descent. Since W is typically large in LLMs, storing and computing ΔW is expensive.
LoRA Approximation
LoRA constrains the update ΔW within a low-rank space as:
ΔW=BA
where A∈Rdin×r, B∈Rr×dout and the rank r≪min(din,dout).
Thus, instead of updating a full ΔW∈Rdin×dout, only two smaller matrices A and B need to be updated.
LoRA Forward Pass
In LoRA, the adapted weight matrix is:
W←W+rαBA
where α is a scaling factor to control the magnitude of adaptation:
Small α: Tend to retain more of the pretrained knowledge
Large α: Tend to learn features of new tasks
α/r: Ensure that update magnitudes remain stable across different choices of r
Implementation: A Simple LoRA Linear Layer
classLoRALinear(nn.Module):
def__init__( self, in_feats: int, out_feats: int, rank: int, alpha: float, dropout: float = 0.0, bias: bool = False, ) -> None: """LoRA Linear layers as described in the paper "LoRA: Low-Rank Adaptation of Large Language Models". Args: in_feats (int): Input dimension. out_feats (int): Output dimension. rank (int): Rank of the low-rank approximation. alpha (float): Scaling factor. dropout (float, optional): Dropout probability. Defaults to 0.0. bias (bool, optional): Whether to include bias in the original linear layer. Defaults to False. """ super().__init__() # weights from the original pretrained model self.linear = nn.Linear(in_feats, out_feats, bias=bias)
# extra LoRA params. In general, rank << min(in_feats, out_feats) self.lora_a = nn.Linear(in_feats, rank, bias=False) self.lora_b = nn.Linear(rank, out_feats, bias=False)
# most implementations also include some dropout self.dropout = nn.Dropout(dropout)
# original params are frozen, and only LoRA params are trainable. # self.lora_a.weight.requires_grad = True # self.lora_b.weight.requires_grad = True self.linear.weight.requires_grad = False
# initialize the LoRA params self._init_params()
def_init_params(self) -> None: """Initialize the parameters.""" nn.init.kaiming_normal_(self.lora_a.weight, a=math.sqrt(5)) nn.init.zeros_(self.lora_b.weight)
defforward(self, x: torch.Tensor) -> torch.Tensor: """Forward pass. Args: x (torch.Tensor): Input tensor of shape (..., in_feats). Returns: torch.Tensor: Output tensor of shape (..., out_feats). """ # the output of the original model frozen_out = self.linear(x)
# lora_a projects inputs down to the much smaller self.rank, # then lora_b projects back up to the output dimension lora_out = self.lora_b(self.lora_a(self.dropout(x)))
# Finally, scale by the alpha parameter (normalized by rank) # and add to the original model's outputs return frozen_out + (self.alpha / self.rank) * lora_out