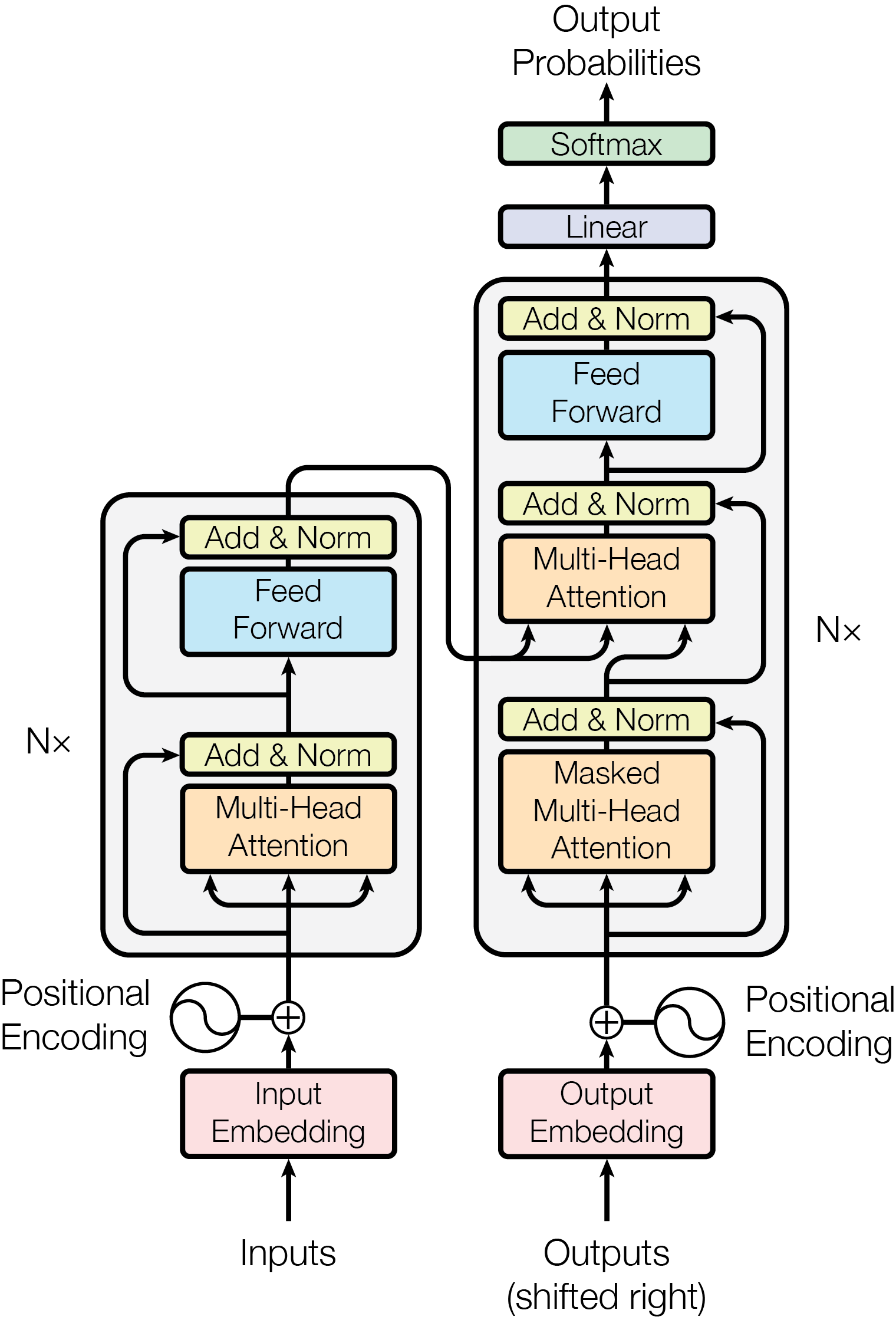
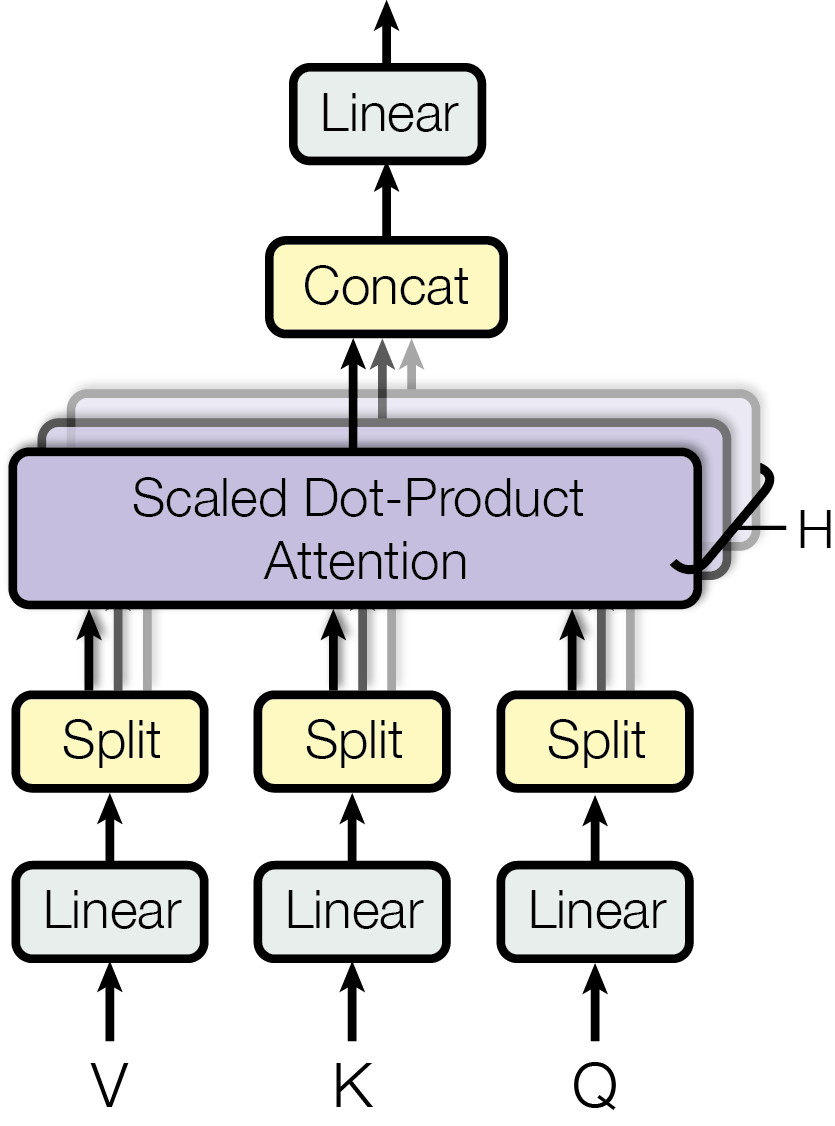
def__init__( self, n_embd: int, n_head: int, attn_pdrop: float = 0.1, resid_pdrop: float = 0.1, bias: bool = True, ) -> None: """Initialize the module. Args: n_embd (int): Embedding dimension. n_head (int): Number of attention heads. attn_pdrop (float): Dropout probability for attention weights. Defaults to 0.1. resid_pdrop (float): Dropout probability for residual connections. Defaults to 0.1. bias (bool, optional): Whether to include bias terms when calculating k, q, v projections. Defaults to True. """ super().__init__() assert n_embd % n_head == 0# n_embd must be divisible by n_head # key, query, value projections for all heads, but in a batch self.c_attn = nn.Linear(n_embd, 3 * n_embd, bias=bias) # output projection self.c_proj = nn.Linear(n_embd, n_embd, bias=bias) # regularization self.attn_dropout = nn.Dropout(attn_pdrop) self.resid_dropout = nn.Dropout(resid_pdrop) self.n_head = n_head
defforward(self, x: torch.Tensor) -> torch.Tensor: """Forward pass. Args: x (torch.Tensor): Input tensor of shape (B, T, C) where B is the batch size, T is the sequence length, C is the embedding dimension. Returns: torch.Tensor: Output tensor of shape (B, T, C). """ # B: batch size, T: sequence length, C: embedding dimension (=n_embd) B, T, C = x.size()
# calculate q, k, v for all heads in batch # (B, T, C) -> (B, T, 3C) -> (B, T, C) x 3 q, k, v = self.c_attn(x).split(C, dim=-1) # move head dim forward to be the batch dim # (B, T, C) -> (B, T, nh, hs) -> (B, nh, T, hs) # C = nh * hs, where nh: number of heads, hs: head size, q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
attn_weights = (q @ k.transpose(-2, -1)) * ( 1.0 / math.sqrt(k.size(-1)) # scaling factor ) # (B, nh, T, hs) x (B, nh, hs, T) = (B, nh, T, T) attn_weights = torch.softmax(attn_weights, dim=-1) attn_weights = self.attn_dropout(attn_weights) # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs) y = attn_weights @ v # re-assemble all head outputs side by side y = ( y.transpose(1, 2) # (B, T, nh, hs) .contiguous() # equivalent to `.reshape(B, T, C)` .view(B, T, C) # (B, T, C) )
# output projection returnself.resid_dropout(self.c_proj(y)) # (B, T, C)
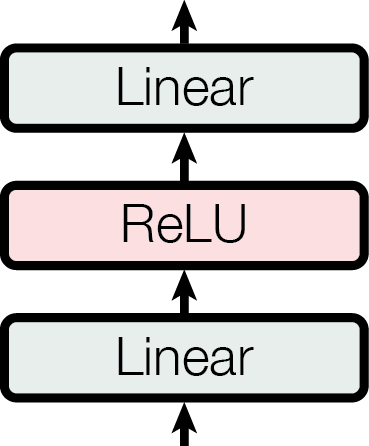
defforward(self, x: torch.Tensor) -> torch.Tensor: """Forward pass. Args: x (torch.Tensor): Input tensor of shape (B, T, C) where B is the batch size, T is the sequence length, C is the embedding dimension. Returns: torch.Tensor: Output tensor of shape (B, T, C). """ returnself.net(x)
def__init__( self, n_embd: int, n_head: int, attn_pdrop: float = 0.1, resid_pdrop: float = 0.1, ffn_pdrop: float = 0.1, ) -> None: """Initialize the module. Args: n_embd (int): Embedding dimension. n_head (int): Number of attention heads. attn_pdrop (float): Dropout probability for attention weights. Defaults to 0.1. resid_pdrop (float): Dropout probability for residual connections. Defaults to 0.1. ffn_pdrop (float): Dropout probability for feed-forward network. Defaults to 0.1. """ super().__init__() self.attn = SelfAttention(n_embd, n_head, attn_pdrop, resid_pdrop) self.norm1 = nn.LayerNorm(n_embd) self.ffn = FFN(n_embd, ffn_pdrop) self.norm2 = nn.LayerNorm(n_embd)
defforward(self, x: torch.Tensor) -> torch.Tensor: """Forward pass. Args: x (torch.Tensor): Input tensor of shape (B, T, C) where B is the batch size, T is the sequence length, C is the embedding dimension. Returns: torch.Tensor: Output tensor of shape (B, T, C). """ # self-attention -> add & norm x = self.norm1(x + self.attn(x)) # feed-forward -> add & norm x = self.norm2(x + self.ffn(x)) return x
decoder 是自回归模型。在推理阶段,预测序列中第 t 个词时,只能依赖前 t 个词,而无法看到后续位置的信息。为了保持训练与推理的一致性 (即:在训练与推理时使用相同的生成策略),decoder 使用 mask 屏蔽未来信息。
简单实现如下:
B, T, C = 4, 8, 32# batch_size, seq_len, embed_size # calculate attention weights k = torch.randn(B, T, C) # (B, T, C) q = torch.randn_like(k) # (B, T, C) attn_weights = q @ k.transpose(-2, -1) # (B, T, T) # create a lower triangular mask # i.e. the lower triangle (including the diagonal) is 1, and the rest is 0. mask = torch.tril(torch.ones(T, T)) # (T, T) # mask out the upper half of the matrix (i.e., future positions) with -inf attn_weights.masked_fill_(mask == 0, float("-inf")) # -inf will become 0 after applying softmax attn_weights = torch.softmax(attn_weights, dim=-1)
具体实现时,可将 mask 张量提前计算并缓存,如下:
classCausalSelfAttention(nn.Module):
def__init__( self, n_embd: int, n_positions: int, n_head: int, attn_pdrop: float = 0.1, resid_pdrop: float = 0.1, bias: bool = True, ) -> None: """Initialize the module. Args: n_embd (int): Embedding dimension. n_positions (int): Maximum sequence length. n_head (int): Number of attention heads. attn_pdrop (float): Dropout probability for attention weights. Defaults to 0.1. resid_pdrop (float): Dropout probability for residual connections. Defaults to 0.1. bias (bool, optional): Whether to include bias terms when calculating k, q, v projections. Defaults to True. """ super().__init__() assert n_embd % n_head == 0# n_embd must be divisible by n_head # key, query, value projections for all heads, but in a batch self.c_attn = nn.Linear(n_embd, 3 * n_embd, bias=bias) # output projection self.c_proj = nn.Linear(n_embd, n_embd, bias=bias) # regularization self.attn_dropout = nn.Dropout(attn_pdrop) self.resid_dropout = nn.Dropout(resid_pdrop) self.n_head = n_head # precompute and cache mask self.register_buffer( "mask", torch.tril(torch.ones(n_positions, n_positions)).view( 1, 1, n_positions, n_positions ), )
defforward(self, x: torch.Tensor) -> torch.Tensor: """Forward pass. Args: x (torch.Tensor): Input tensor of shape (B, T, C) where B is the batch size, T is the sequence length, C is the embedding dimension. Returns: torch.Tensor: Output tensor of shape (B, T, C). """ # B: batch size, T: sequence length, C: embedding dimension (=n_embd) B, T, C = x.size()
# calculate q, k, v for all heads in batch # (B, T, C) -> (B, T, 3C) -> (B, T, C) x 3 q, k, v = self.c_attn(x).split(C, dim=-1) # move head dim forward to be the batch dim # (B, T, C) -> (B, T, nh, hs) -> (B, nh, T, hs) # C = nh * hs, where nh: number of heads, hs: head size, q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
attn_weights = (q @ k.transpose(-2, -1)) * ( 1.0 / math.sqrt(k.size(-1)) # scaling factor ) # (B, nh, T, hs) x (B, nh, hs, T) = (B, nh, T, T) attn_weights.masked_fill_(self.mask[:, :, :T, :T] == 0, float("-inf")) attn_weights = torch.softmax(attn_weights, dim=-1) attn_weights = self.attn_dropout(attn_weights) # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs) y = attn_weights @ v # re-assemble all head outputs side by side y = ( y.transpose(1, 2) # (B, T, nh, hs) .contiguous() # equivalent to `.reshape(B, T, C)` .view(B, T, C) # (B, T, C) )
# output projection returnself.resid_dropout(self.c_proj(y)) # (B, T, C)
def__init__( self, n_embd: int, n_positions: int, n_head: int, attn_pdrop: float = 0.1, resid_pdrop: float = 0.1, bias: bool = True, ) -> None: """Initialize the module. Args: n_embd (int): Embedding dimension. n_positions (int): Maximum sequence length. n_head (int): Number of attention heads. attn_pdrop (float): Dropout probability for attention weights. Defaults to 0.1. resid_pdrop (float): Dropout probability for residual connections. Defaults to 0.1. bias (bool, optional): Whether to include bias terms when calculating k, q, v projections. Defaults to True. """ super().__init__() assert n_embd % n_head == 0# n_embd must be divisible by n_head # key, query, value projections for all heads self.key = nn.Linear(n_embd, n_embd, bias=bias) self.value = nn.Linear(n_embd, n_embd, bias=bias) self.query = nn.Linear(n_embd, n_embd, bias=bias) # output projection self.proj = nn.Linear(n_embd, n_embd, bias=bias) # regularization self.attn_dropout = nn.Dropout(attn_pdrop) self.resid_dropout = nn.Dropout(resid_pdrop) self.n_head = n_head # precompute and cache mask self.register_buffer( "mask", torch.tril(torch.ones(n_positions, n_positions)).view( 1, 1, n_positions, n_positions ), )
defforward(self, x_kv: torch.Tensor, x_q: torch.Tensor) -> torch.Tensor: """Forward pass. Args: x_kv (torch.Tensor): Input tensor of shape (B, Tk, C) where B is the batch size, Tk is the sequence length for keys and values C is the embedding dimension. x_q (torch.Tensor): Input tensor of shape (B, Tq, C) where Tq is the sequence length for queries Returns: torch.Tensor: Output tensor of shape (B, Tq, C). """ Bk, Tk, Ck = x_kv.size() Bq, Tq, Cq = x_q.size() assert Bk == Bq and Ck == Cq
# calculate q, k, v for all heads q = ( self.query(x_q) # (B, Tq, C) .view(Bq, Tq, self.n_head, Cq // self.n_head) # (B, Tq, nh, hs) .transpose(1, 2) # (B, nh, Tq, hs) ) k = ( self.key(x_kv) # (B, Tk, C) .view(Bk, Tk, self.n_head, Ck // self.n_head) # (B, Tk, nh, hs) .transpose(1, 2) # (B, nh, Tk, hs) ) v = ( self.value(x_kv) # (B, Tk, C) .view(Bk, Tk, self.n_head, Ck // self.n_head) # (B, Tk, nh, hs) .transpose(1, 2) # (B, nh, Tk, hs) )
# causal self-attention attn_weights = (q @ k.transpose(-2, -1)) * ( 1.0 / math.sqrt(k.size(-1)) # scaling factor ) # (B, nh, Tq, hs) x (B, nh, hs, Tk) = (B, nh, Tq, Tk) attn_weights.masked_fill_(self.mask[:, :, :Tq, :Tk] == 0, float("-inf")) attn_weights = torch.softmax(attn_weights, dim=-1) attn_weights = self.attn_dropout(attn_weights) # (B, nh, Tq, Tk) x (B, nh, Tk, hs) -> (B, nh, Tq, hs) y = attn_weights @ v # re-assemble all head outputs side by side y = ( y.transpose(1, 2) # (B, Tq, nh, hs) .contiguous() # equivalent to `.reshape(B, Tq, C)` .view(Bk, Tk, Ck) # (B, Tq, C) )
# output projection returnself.resid_dropout(self.proj(y)) # (B, Tq, C)